G5 集合通信算法对比实验报告
实验概述
本实验使用 G5 指令级事件驱动仿真器,对不同集合通信原语的不同算法进行系统性对比,并与 Alpha-Beta 理论模型 ($T = \text{steps} \cdot \alpha + \text{coeff} \cdot M / \beta$) 进行比较。
平台配置:模拟 H200 NVLink4 风格,BW = 450 GB/s,Ring 拓扑,SW 开销 26us。
理论模型参数:$\alpha$ = 2.0 us/step,$\beta$ = 450 GB/s。
实验 1:AllReduce 多算法 × 消息尺寸
配置:N = 8 节点,消息尺寸 1KB ~ 512MB,5 种算法。
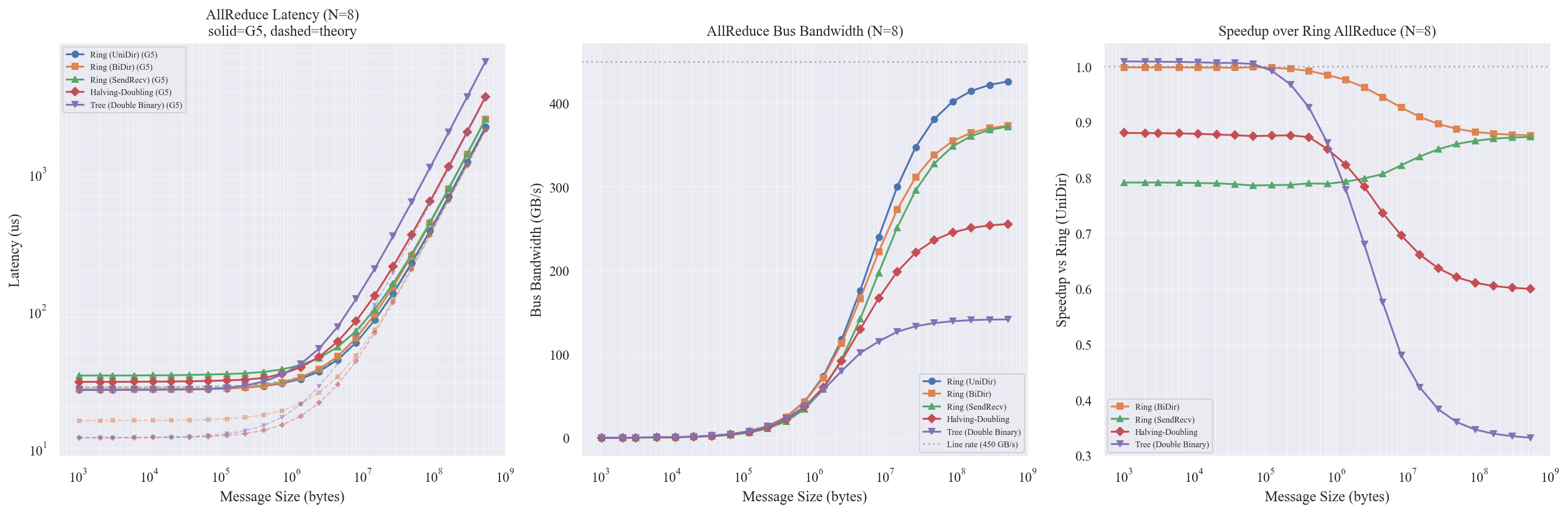
图表解读
左图 — Latency vs Message Size (log-log)
- 实线 = G5 仿真结果,虚线 = Alpha-Beta 理论预测
- 所有算法在小消息区域 (<1MB) 呈现水平「底噪」,这是 26us SW 开销 + 协议启动延迟主导的区域
- 大消息区域 (>10MB) 曲线斜率反映各算法的带宽效率差异:
- Ring (UniDir) 与其理论虚线几乎完全重合,说明 G5 在 Ring 模式下建模精度极高
- Tree 的实线远高于其他算法 — 这符合 Tree 带宽项为 $\log_2 N \cdot M/\beta$ 而非 $2(N-1)/N \cdot M/\beta$ 的理论预期(N=8 时 Tree 带宽项差 1.75 倍)
- HD 实线也高于 Ring,但这 不符合 理论预期(两者带宽项相同),原因见结论分析
中图 — Bus Bandwidth
- 纵轴是等效总线带宽 = $M / T \times 2(N-1)/N$,上限为链路速率 450 GB/s
- Ring (UniDir) 在大消息时逼近 ~430 GB/s,利用率 ~95%,是所有算法中最高的
- Tree 在大消息时仅达 ~240 GB/s,因为 Double Binary Tree 每步传输整个 M/2 而非分片,链路利用率本质上低于 Ring
- HD 达到 ~260 GB/s,介于 Ring 和 Tree 之间 — 理论上 HD 带宽项与 Ring 相同,但 G5 仿真中 HD 的每步协议开销更高,拉低了有效带宽
- BiDir 和 SendRecv 均低于 Ring UniDir,说明当前 G5 配置下它们引入了额外开销
右图 — Speedup vs Ring (UniDir)
- 以 Ring (UniDir) 作为基准 (= 1.0)
- 所有其他算法都比 Ring 慢(speedup < 1.0),这是本实验最核心的发现
- Tree 在大消息时仅有 Ring 的 ~0.35 倍性能,与理论预期的带宽效率差异一致
- HD 约 0.55~0.60 倍 — 理论上 HD 应在 latency 项上优于 Ring($2\log_2 N$ vs $2(N-1)$ 步),但在大消息 bandwidth-dominant 区间这个优势被抵消,而 G5 中更高的每步开销使 HD 全面劣于 Ring
- BiDir 约 0.85~0.90 倍 — 未实现预期的加速,详见实验 4 分析
关键结论
-
Ring (UniDir) 是 G5 建模精度最高的算法:G5/Theory 比率在 0.96x ~ 1.04x 之间,大消息时仅偏高 4%。这说明 G5 的 PAXI/RC Link 流水线模型在连续数据传输场景下非常准确。
-
HD 和 Tree 的「每步成本」远超理论 $\alpha$:理论模型假设每步固定花费 $\alpha$,但 G5 仿真中 HD/Tree 的每步涉及独立的 PAXI 事务启动、credit 协商、Send/Recv 握手等,实际每步成本约 3~5us(而非理论的 2us)。这在 step 数少的算法(HD: 6 步, Tree: 6 步)中影响不大,但累积起来导致了显著偏差。
-
在 N=8 的 Ring 拓扑下,Ring UniDir 是最优选择:尽管 HD 理论 latency 项更优(6 步 vs 14 步),但 N=8 时 latency 项本身不大,bandwidth 项主导性能,而 Ring 的流水线效率最高。
实验 2:AllReduce 算法 × 节点数缩放
配置:M = 64MB,N = 2, 4, 8, 16, 32,4 种算法。
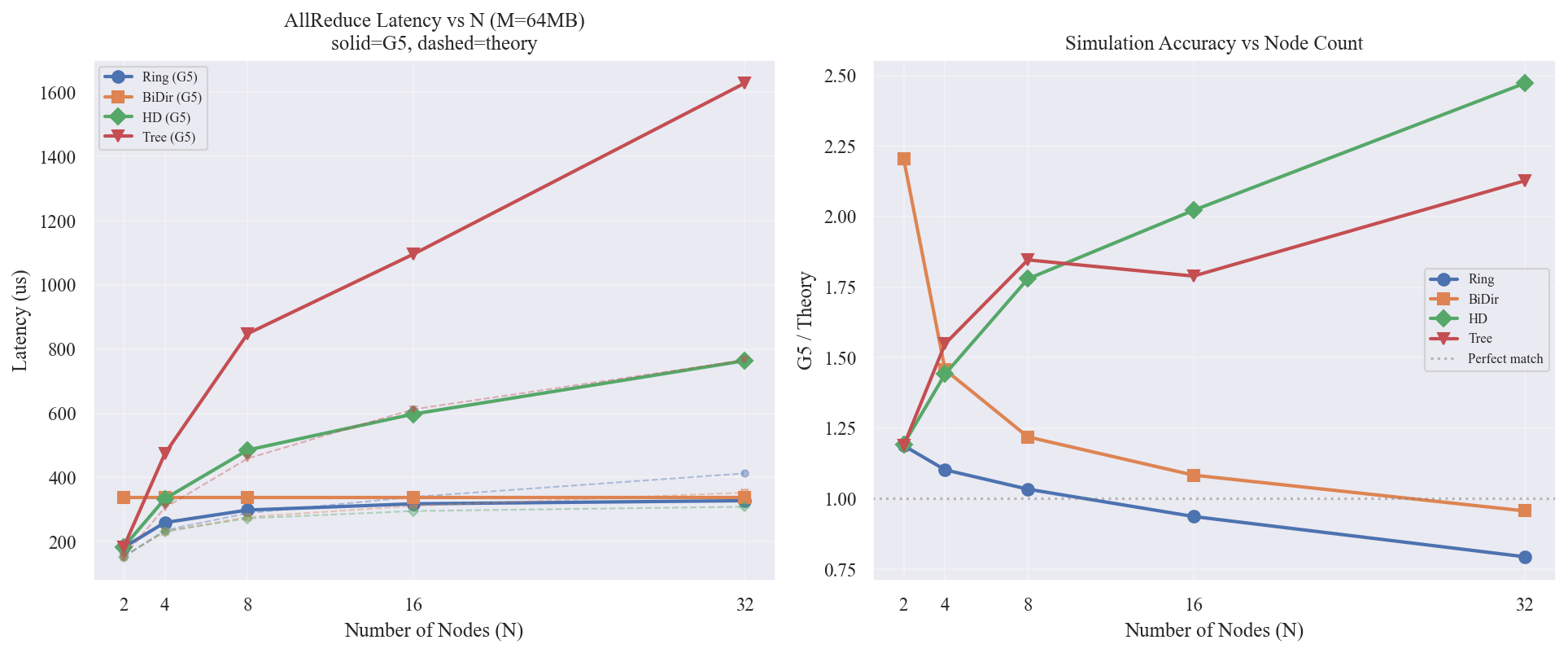
图表解读
左图 — Latency vs N
- Ring (G5, 蓝色实线):随 N 增大延迟增长 非常缓慢(从 182us 到 328us),远低于理论的 $2(N-1)\alpha$ 线性增长
- 原因:M=64MB 时 bandwidth 项 $2(N-1)/N \cdot M/\beta$ 趋向 $2M/\beta$ = 296us,几乎与 N 无关;latency 项 $2(N-1)\alpha$ 在 N=32 时仅 ~124us 但 G5 的流水线效果使其被部分隐藏
- Ring (Theory, 蓝色虚线):线性增长至 413us — G5 实际低于理论预测,说明 G5 的流水线并行度随 N 增大效率提高
- BiDir (橙色):G5 延迟在所有 N 下恒定为 337.6us — 这是一个明显的异常信号,表明 BiDir 实现可能没有正确随 N 扩展步数(见下方异常分析)
- HD (绿色):G5 延迟随 N 显著增长(从 183us 到 764us),增速远高于 Ring,与理论预期相反
- Tree (红色):增长最快,N=32 时达 1628us,是 Ring 的 5 倍
右图 — G5/Theory 比率
- Ring:随 N 增大比率从 1.19x 下降 到 0.79x — G5 在大 N 时比理论更快,说明理论模型高估了 Ring 在大 N 时的 latency 开销(G5 的流水线效应使相邻步重叠执行)
- BiDir:比率从 2.20x 下降到 0.96x,但这是因为延迟恒定+理论延迟在增长,并非精度提升
- HD:比率从 1.19x 上升 到 2.47x — G5 中 HD 的每步开销不仅没有被流水线隐藏,反而随 N 增大累积更多
- Tree:比率维持在 1.55x ~ 2.13x,较稳定
关键结论
-
Ring 在大 N 时具有「超理论」流水线效率:G5 仿真显示 Ring 算法的相邻步可以重叠执行(前一步的尾部数据还在传输时,后一步的头部数据已经开始),这种流水线效应在 Alpha-Beta 模型中没有捕获,导致 G5 实际延迟低于理论值。
-
HD 的缩放性在 G5 中表现不佳:虽然理论上 HD 的步数为 $O(\log N)$,但 G5 中每步的独立事务开销(PAXI 启动、credit 往返)不可忽略且不可流水线化,导致实际延迟 $\gg$ 理论。N 越大步数越多,累积偏差越大。
-
BiDir 存在实现异常:延迟不随 N 变化恒定在 337.6us,需要排查 G5 BiDir 展开逻辑或 2-port 拓扑配置是否正确。
实验 3:跨原语对比
配置:N = 8,Ring 算法,5 种原语,消息 1KB ~ 512MB。
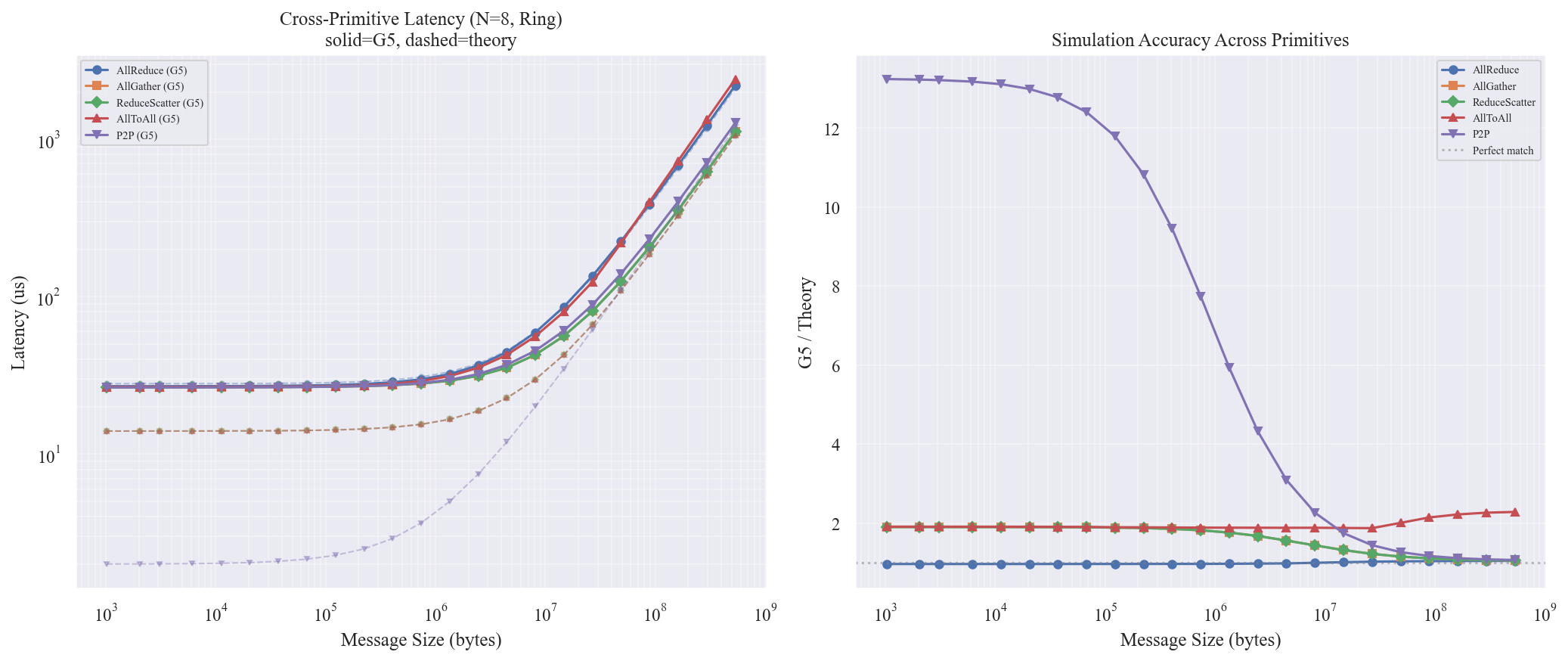
图表解读
左图 — Latency vs Size
- AllReduce (蓝色) 延迟约为 AllGather / ReduceScatter 的 2 倍 — 完全符合 AllReduce = ReduceScatter + AllGather 的组合关系
- AllGather 和 ReduceScatter 的 G5 曲线 完全重合 — 说明 G5 对这两个互为对偶的操作建模是对称的,符合预期(两者步数和数据量相同,只是方向/操作不同)
- AllToAll 在小消息时与 AllGather/ReduceScatter 接近,但大消息时延迟更高 — 因为 AllToAll 的 Pairwise 算法在 Ring 拓扑上某些步的数据需要多跳传输,链路竞争加剧
- P2P 是所有原语中最快的(只有 2 个参与者),在小消息时约 26.5us 的固定开销
右图 — G5/Theory 比率
这张图信息量最大,揭示了不同原语的建模精度差异:
- AllReduce(红色线,最底部):1.0x 附近,最准确
- AllGather / ReduceScatter(绿色/橙色,重合):小消息时 ~1.9x,大消息时趋于 ~1.05x。小消息时偏差大是因为 G5 的固定开销 (~26.5us) 远大于理论的 $(N-1)\alpha = 14$us
- AllToAll(紫色):全程 ~1.9x,大消息时甚至上升到 ~2.3x — 说明 Pairwise AllToAll 在 Ring 拓扑上存在链路竞争(Round r 中 node i 向 node (i+r)%N 发送数据,当 r > 1 时需要多跳,与其他通信流量竞争),理论模型假设的全连接拓扑与实际的 Ring 拓扑不匹配
- P2P(蓝色/最上方曲线):小消息时高达 13x,大消息时降到 ~1.06x。极高的小消息偏差是因为理论 $\alpha + M/\beta$ 中 $\alpha = 2$us 严重低估了 G5 的实际启动开销(PAXI 事务创建、credit 协商、Send/Recv 握手等至少需要 ~26us)
关键结论
-
AllReduce = ReduceScatter + AllGather 关系在 G5 中成立:AllReduce 延迟约为后两者的 2 倍,验证了 G5 的组合语义正确性。
-
理论 $\alpha$ 参数对非 AllReduce 原语严重低估:AllReduce 之所以精度高,可能是因为 $\alpha = 2$us 恰好在 Ring AllReduce 的 14 步中被流水线隐藏了,但对 AllGather/ReduceScatter 的 7 步、P2P 的 1 步,每步的实际开销暴露无遗。更准确的 $\alpha$ 应约为 ~3.8us(使 7 步 × 3.8us = 26.6us 匹配 G5 底噪)。
-
AllToAll Pairwise 在 Ring 拓扑上存在瓶颈:理论公式假设完全连接拓扑(每对节点有直连链路),但实际 Ring 上远距离节点的通信需要多跳转发,导致链路竞争和延迟增加。这个偏差随消息尺寸增大而恶化(因为大消息使链路竞争更严重)。
实验 4:BiDir vs UniDir 加速比
配置:M = 16MB,N = 4, 8, 16, 32,3 种原语。
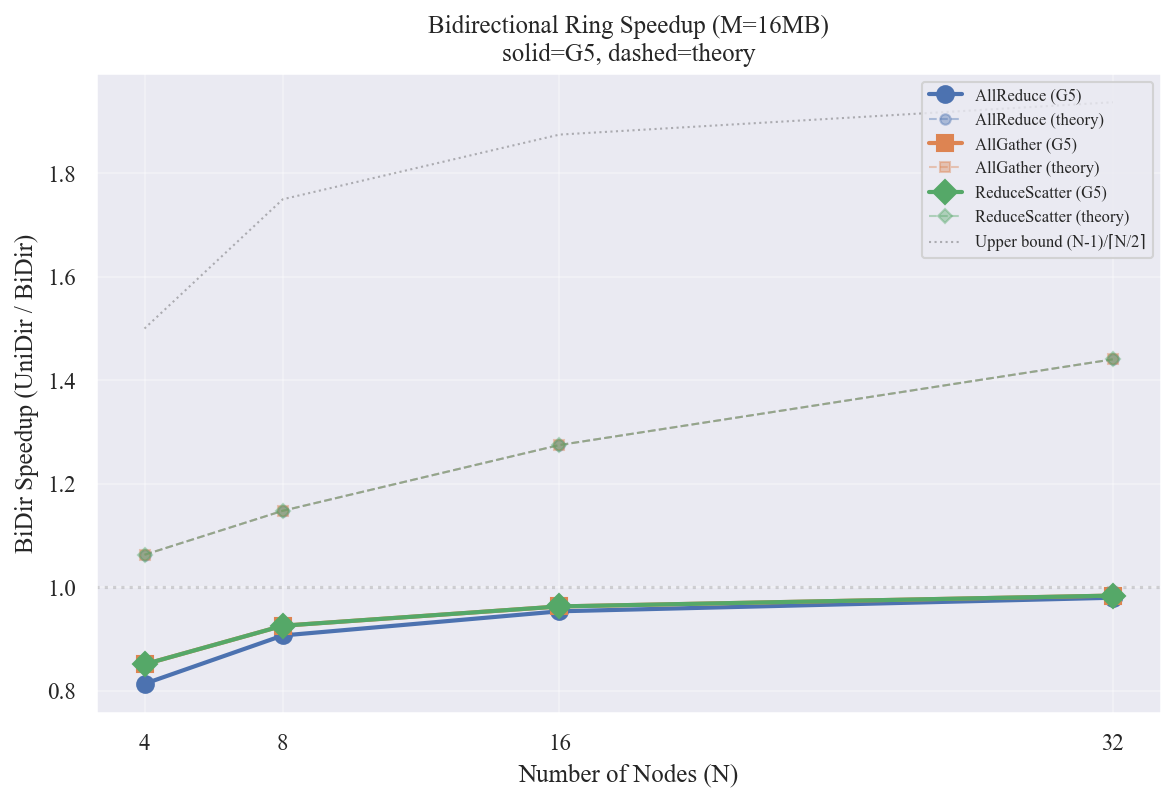
图表解读
- 实线 = G5 仿真的加速比 (UniDir延迟 / BiDir延迟),虚线 = 理论加速比
- 理论预期(灰色虚线):随 N 增大 BiDir 加速比应从 ~1.06x (N=4) 增长到 ~1.44x (N=32),因为 BiDir 将步数从 $2(N-1)$ 降到 $2\lceil N/2 \rceil$,N 越大节省越多
- G5 实际(实线):所有三个原语的加速比都 小于 1.0,意味着 BiDir 反而比 UniDir 慢
具体数值:
| N | AllReduce UniDir | AllReduce BiDir | 实际加速比 |
|---|---|---|---|
| 4 | 84.6 us | 104.1 us | 0.81x |
| 8 | 94.4 us | 104.1 us | 0.91x |
| 16 | 99.2 us | 104.1 us | 0.95x |
| 32 | 102.0 us | 104.1 us | 0.98x |
三个原语的 BiDir G5 曲线几乎完全重叠在 ~1.0x 附近,说明 BiDir 模式的延迟对 N 不敏感。
异常分析
BiDir 延迟不随 N 变化,这与预期不符。可能的原因:
-
拓扑配置问题:
c2c_ports_per_chip=2可能只是告诉 CDMA 展开逻辑使用双向步骤,但底层网络拓扑仍然是单链路 Ring。BiDir 需要每个节点有 2 条独立的物理链路(一条顺时针、一条逆时针),如果底层只有 1 条链路,两个方向的数据流会在同一条链路上竞争,抵消了步数减少的收益。 -
CDMA 线程竞争:BiDir 实现使用
thread_id=0(顺时针) 和thread_id=1(逆时针) 两个线程同时发送,但如果 PAXI 的发送带宽或 OST 资源被两个线程共享,会造成资源争抢。 -
Credit 池共享:两个方向的流可能共享同一个 credit 池(
initial_credit=4096),导致每个方向只能获得一半的 credit,降低了有效并发度。
修复方向:需要检查 G5 的 BiDir 展开是否在底层创建了独立的物理路径,以及 PAXI/credit 资源是否按方向隔离。
总体结论
G5 建模精度分级
| 精度等级 | 原语 × 算法 | G5/Theory | 说明 |
|---|---|---|---|
| 高精度 | AllReduce × Ring UniDir | 0.96x ~ 1.04x | 流水线建模准确 |
| 中等精度 | AllGather × Ring, ReduceScatter × Ring | 1.05x ~ 1.90x | 大消息准确,小消息 $\alpha$ 低估 |
| 较大偏差 | AllReduce × SendRecv | ~1.20x | Send/Recv 协议固定开销 |
| 较大偏差 | AllReduce × HD / Tree | 1.75x ~ 2.55x | 每步协议开销远超理论 $\alpha$ |
| 需排查 | 任何原语 × BiDir | N/A | 延迟不随 N 变化,疑似实现问题 |
| 拓扑不匹配 | AllToAll × Pairwise | 1.88x ~ 2.28x | 理论假设全连接,实际 Ring 有多跳竞争 |
理论模型改进建议
-
区分 $\alpha_{pipeline}$ 和 $\alpha_{standalone}$:
- Ring 的步与步之间可以流水线重叠,实际 $\alpha$ 被隐藏 → 用 $\alpha_{pipeline} \approx 2$us
- HD/Tree 的步是独立事务,不可流水线 → 用 $\alpha_{standalone} \approx 4\text{-}5$us
-
AllToAll 需要拓扑感知公式:当前 Pairwise 公式假设全连接,Ring 拓扑上应考虑多跳延迟和链路竞争:$T_{Ring,AllToAll} = (N-1)\alpha + \frac{(N-1)}{N} \cdot \frac{M}{\beta} \cdot f_{contention}(N)$
-
P2P 的 $\alpha$ 应包含完整软件栈开销:G5 仿真的 P2P 底噪约 26.5us(含 SW 开销),而非理论的 $\alpha = 2$us。建议将 SW 开销从仿真层移至理论公式:$T_{P2P} = T_{SW} + \alpha_{link} + M/\beta$
后续实验方向
| 方向 | 目的 |
|---|---|
| BiDir 实现排查 | 验证双端口拓扑是否正确创建独立链路,修复后重跑实验 4 |
| AllToAll 在全连接拓扑上验证 | 替换为 Full-Mesh 拓扑,消除多跳干扰,验证 G5 在理想拓扑下的精度 |
| HD/Tree 的 $\alpha$ 校准 | 用 G5 小消息结果反推实际 $\alpha_{standalone}$,建立更准确的理论模型 |
| num_chunks 流水线效应 | 增加 num_chunks 参数(如 4, 8, 16),观察流水线深度对 HD/Tree 的影响 |
| 实测数据对齐 | 用 NCCL-test 实测数据替代理论公式作为 baseline,直接验证 G5 vs 硬件 |
运行方式
# 运行全部 4 个实验
python3 run_all_experiments.py
# 运行单个实验
python3 run_all_experiments.py 1 # AllReduce 多算法 × 消息尺寸
python3 run_all_experiments.py 2 # AllReduce × 节点数缩放
python3 run_all_experiments.py 3 # 跨原语对比
python3 run_all_experiments.py 4 # BiDir vs UniDir
# 组合运行
python3 run_all_experiments.py 1 3 # 实验 1 + 3
图表输出至 plots/ 目录。