互联通信建模验证分析
摘要:本文验证 Tier6-Model 两种评估引擎(Math 代数模型、G5 指令级仿真)在 NVLink3/4/5、PCIe、InfiniBand 等互联类型下的 AllReduce 预测精度。核心结论:(1) 大消息(> 64 MB)Math 模型 RMSPE < 10%,适合推理场景 TP/PP 通信建模;(2) G5 仿真在同场景下与 Math 精度几乎一致(RMSPE 差异 ≤ 2pp),验证了两种引擎的等价性。
背景与目标
AI 集群性能建模中,通信延迟是最不确定的环节。本文量化 Tier6-Model 在不同互联类型和消息大小下的预测误差,验证 Math 和 G5 两种引擎的一致性。
与其他模拟器的精度定位:
| 模拟器 | 通信模型 | 精度(大消息) | 仿真速度 |
|---|---|---|---|
| SimAI + NS-3 | 包级事件驱动 | ~7-9%(裸跑) | 分钟—小时 |
| ASTRA-sim Analytical | alpha-beta + 查表 | ~5% | 毫秒级 |
| Tier6 Math | alpha-beta + 拓扑路由 | ~3-10% | 毫秒级 |
| Tier6 G5 | 指令级事件驱动 | ~3-10% | 秒级 |
误差指标:RMSPE(均方根百分比误差),按消息大小分段:< 1 MB(延迟主导)、1~64 MB(过渡区)、> 64 MB(带宽主导)。
验证数据集
所有 nccl-tests 实测 CSV 存放在 data/benchmarks/comm-data/:
| 文件 | 互联类型 | 规模 | 数据点 | 来源 |
|---|---|---|---|---|
h200_allreduce_8gpu.csv | NVLink4 + NVLS | 8 GPU | 17 | nccl-tests #272 |
a100_allreduce_8gpu.csv | NVLink3 | 8 GPU | 14 | nccl-tests #149 |
a100_allreduce_4gpu_pcie.csv | PCIe Gen4 | 4 GPU | 15 | Ed Sealing |
gb200_allreduce_nvl72_coreweave.csv | NVLink5 | 72 GPU (NVL72) | 5 | CoreWeave |
h100_allreduce_16gpu_2node_crusoe.csv | NVLink4 + IB NDR | 16 GPU (2 node) | 17 | Crusoe |
h100_allreduce_16gpu_2node_ib.csv | NVLink4 + IB NDR | 16 GPU (2 node) | 5 | Nebius |
h100_allreduce_16gpu_2node.csv | NVLink4 + RoCEv2 | 16 GPU (2 node) | 5 | Oracle |
a100_allreduce_16gpu_2node.csv | NVLink3 + RDMA | 16 GPU (2 node) | 11 | Oracle |
gh200_allreduce_2gpu_2node_roce.csv | RoCEv2 (BF3) | 2 GPU (2 node) | 29 | Ed Sealing |
h20_allreduce_16gpu_2node_roce_asterfusion.csv | RoCE 400G | 16 GPU (2 node) | 26 | Asterfusion |
拓扑分类:前 4 个为单层全连接(NVSwitch/PCIe),使用 Flat Ring 公式;后 6 个为两层异构(节点内 NVLink + 节点间 IB/RoCE),使用分层 AllReduce 三阶段串行公式。
Math 模型验证结果
单层拓扑
校准参数:$u_r$(带宽利用率)从实测峰值 BusBW 校准,$\ell_{\text{link}}$(每跳链路延迟)从小消息数据拟合。
| 互联类型 | N | $u_r$ | $\ell_{\text{link}}$(μs) | RMSPE |
|---|---|---|---|---|
| NVLink5 (GB200 NVL72) | 72 | 0.96 | 2.1 | 2% |
| NVLink4 (H200 8GPU) | 8 | 0.98 | 1.3 | 9% |
| NVLink3 (A100 8GPU) | 8 | 0.72 | 2.3 | 8% |
| PCIe Gen4 (A100 4GPU) | 4 | 0.66 | — | 1% |
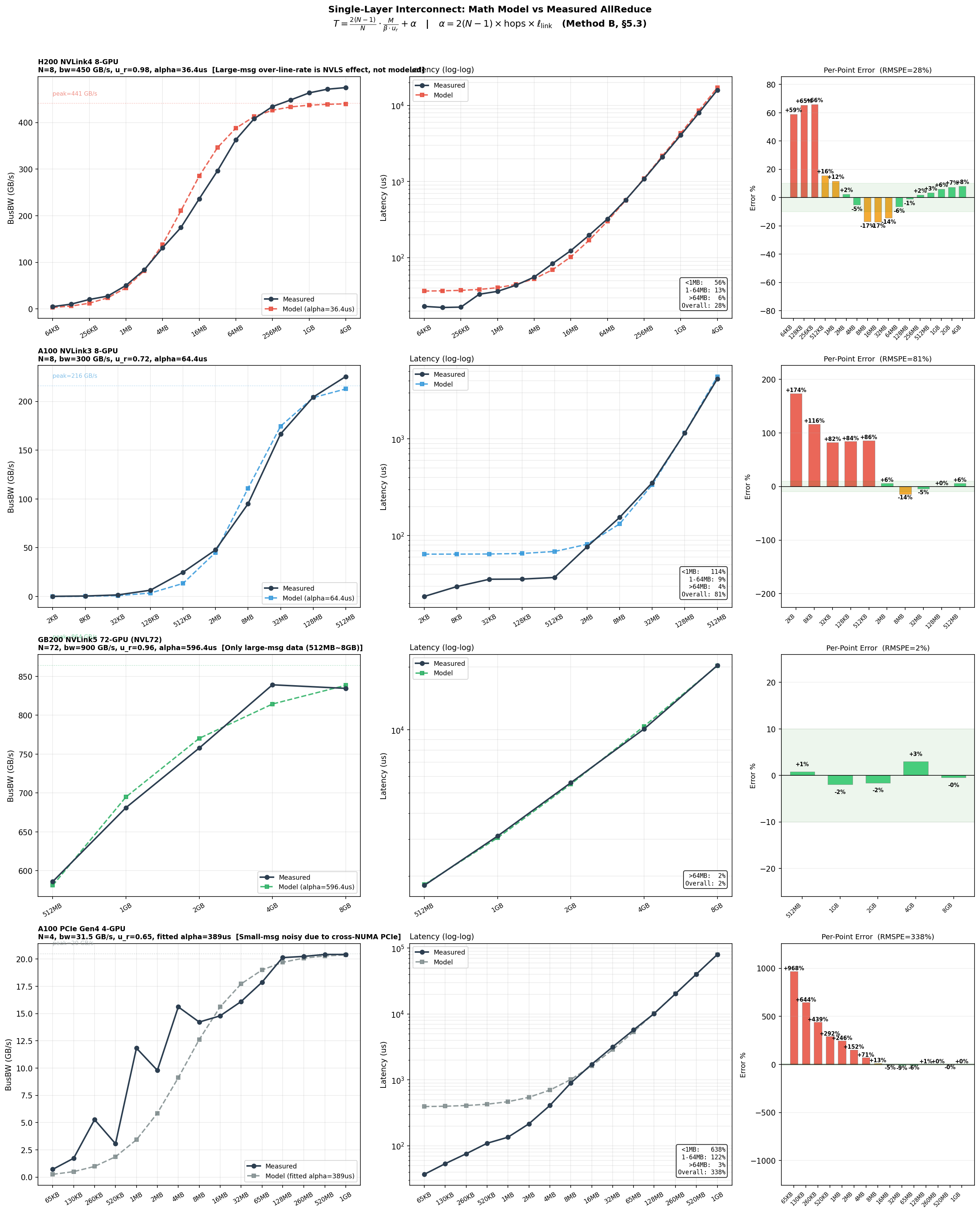
各单层互联类型 AllReduce BusBW 最优拟合结果。黑线实测、绿线拟合。
关键观察:
- $u_r$ 随互联类型差异显著:NVLink4/5 可达 0.96-0.98,NVLink3 仅 0.72,PCIe 仅 0.66。默认值 0.95 对 NVLink3/PCIe 严重高估
- NVLS 超线速:H200 实测 BusBW 475 GB/s 超过 NVLink4 线速 450 GB/s,为 NVSwitch Gen3 网内计算效应,当前模型无法建模
- 模型适用边界:消息 > 64 MB 时误差 < 3%(推理 TP AllReduce 典型大小);消息 < 1 MB 时误差 > 50%
两层拓扑(分层 AllReduce)
对 H100 16-GPU 2-node(NVLink4 + IB NDR)进行网格搜索参数校准(脚本 tests/evaluation/g5/fit_math_16gpu.py):
| 参数 | 最优值 | 搜索范围 |
|---|---|---|
| $u_{NV}$(NVLink 利用率) | 0.92 | 0.85 ~ 0.98 |
| $\beta_{IB}$(IB 有效带宽) | 200 GB/s | 50 ~ 400 GB/s |
| $\alpha_{nv}$(NVLink 固定延迟) | ~15 μs | 0 ~ 30 μs |
| $\alpha_{ib}$(IB 固定延迟) | ~20 μs | 0 ~ 50 μs |
| $T_{sw}$(软件开销) | ~10 μs | 0 ~ 20 μs |
| RMSPE | 9.9% |
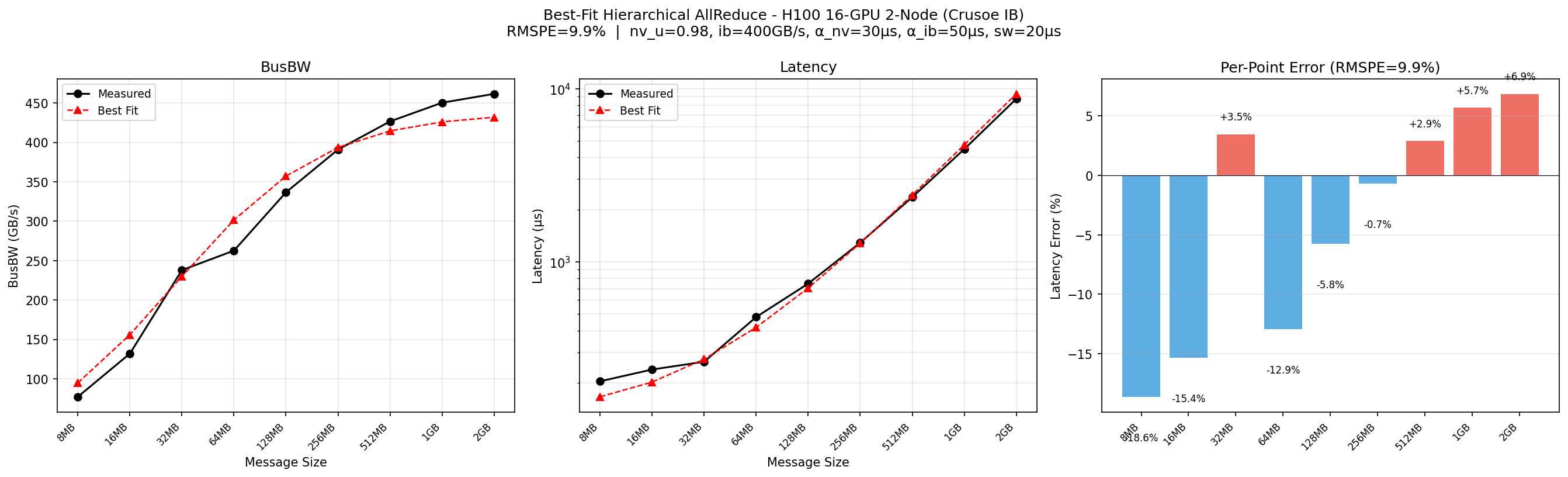
H100 16-GPU 2-node(Crusoe IB)分层 AllReduce 拟合。大消息(> 128 MB)误差 ±10% 以内。
跨节点汇总
对全部跨节点数据集使用分层 AllReduce 公式网格搜索(排除 SHARP 场景):
| 数据集 | 数据点 | 消息范围 | RMSPE | 主要限制 |
|---|---|---|---|---|
| H100 IB NDR(Nebius) | 5 | 512MB ~ 8GB | 7.5% | 仅大消息 |
| H100 RoCEv2(Oracle) | 5 | 1GB ~ 16GB | 5.4% | 仅大消息 |
| GH200 RoCE 2GPU | 21 | 8B ~ 2GB | 33% | 过渡区偏差 |
| A100 RDMA(Oracle) | 11 | 32MB ~ 1GB | 67% | 数据质量存疑 |
| H20 RoCE(Asterfusion) | 24 | 512B ~ 17GB | 57% | ECMP 哈希退化 |
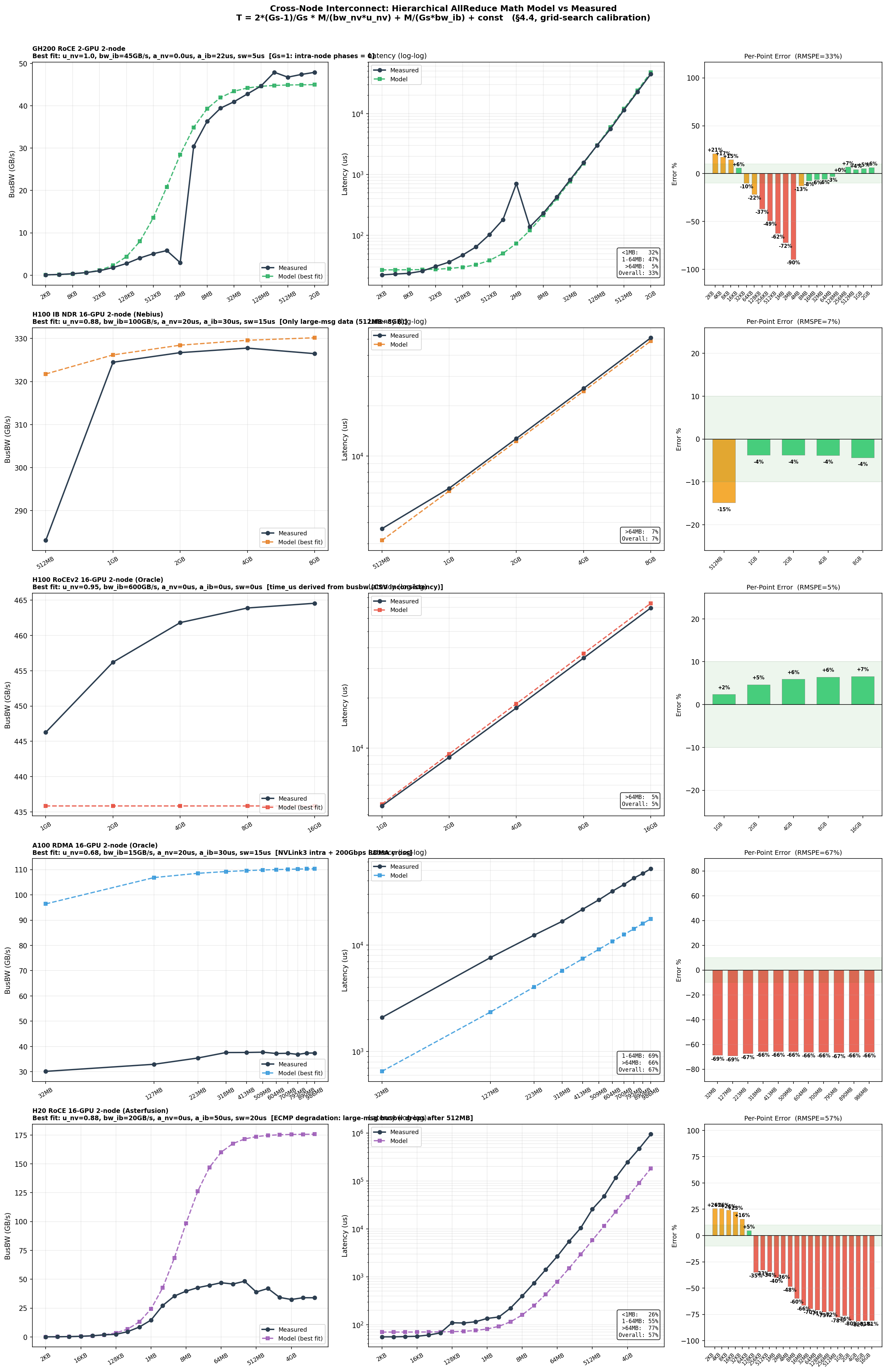
各跨节点互联类型分层 AllReduce 验证。参数均由网格搜索在测量数据上校准。
Math 模型精度边界:
| 场景 | RMSPE | 适用性 |
|---|---|---|
| 单层全连接,大消息(> 64 MB) | < 10% | 推理 TP 场景可用 |
| 两层 IB,大消息 | 8~10% | 多节点 PP 可用 |
| RoCE/RDMA,大消息,无 ECMP | 5~35% | 带宽饱和区可用 |
| ECMP 退化或 SHARP 网内计算 | > 50% | 超出模型范围 |
G5 仿真验证结果
验证方法
G5 是 Rust 实现的指令级事件驱动仿真器(perfmodel/evaluation/g5/),建模 CDMA 传输、PAXI 事务管理、RC Link credit 流控等硬件细节。验证使用与 Math 相同的 nccl-tests 实测数据,在两个单层平台上运行 8-chip Ring AllReduce。
G5 仿真参数:
| 参数 | H200 NVLink4 | A100 NVLink3 |
|---|---|---|
| 芯片数 | 8 | 8 |
| C2C 带宽(线速) | 450 GB/s | 300 GB/s |
| CDMA 有效带宽 | 441 GB/s(× 0.98) | 216 GB/s(× 0.72) |
| SW 开销 | 22 μs | 19 μs |
G5 tier6 CDMA 不使用 efficiency 系数,直接配置有效带宽(= 线速 × $u_r$)使两种引擎的带宽假设对齐。SW 开销 = 实测小消息基线 − G5 硬件固定延迟(约 1.3~1.5 μs)。
Math 校准参数(与 §3.1 一致):
| 参数 | H200 NVLink4 | A100 NVLink3 |
|---|---|---|
| $u_r$ | 0.98 | 0.72 |
| SW 开销 $\alpha$ | 26 μs | 26 μs |
脚本:docs/validation/validate_g5_allreduce.py
验证结果
| 平台 | G5 RMSPE | Math RMSPE | 差异 |
|---|---|---|---|
| H200 NVLink4 8GPU | 7.1% | 5.3% | ~2pp |
| A100 NVLink3 8GPU | 4.3% | 4.2% | < 1pp |
RMSPE 统计范围:大消息段(> 64 MB),与 §3.1 口径一致。
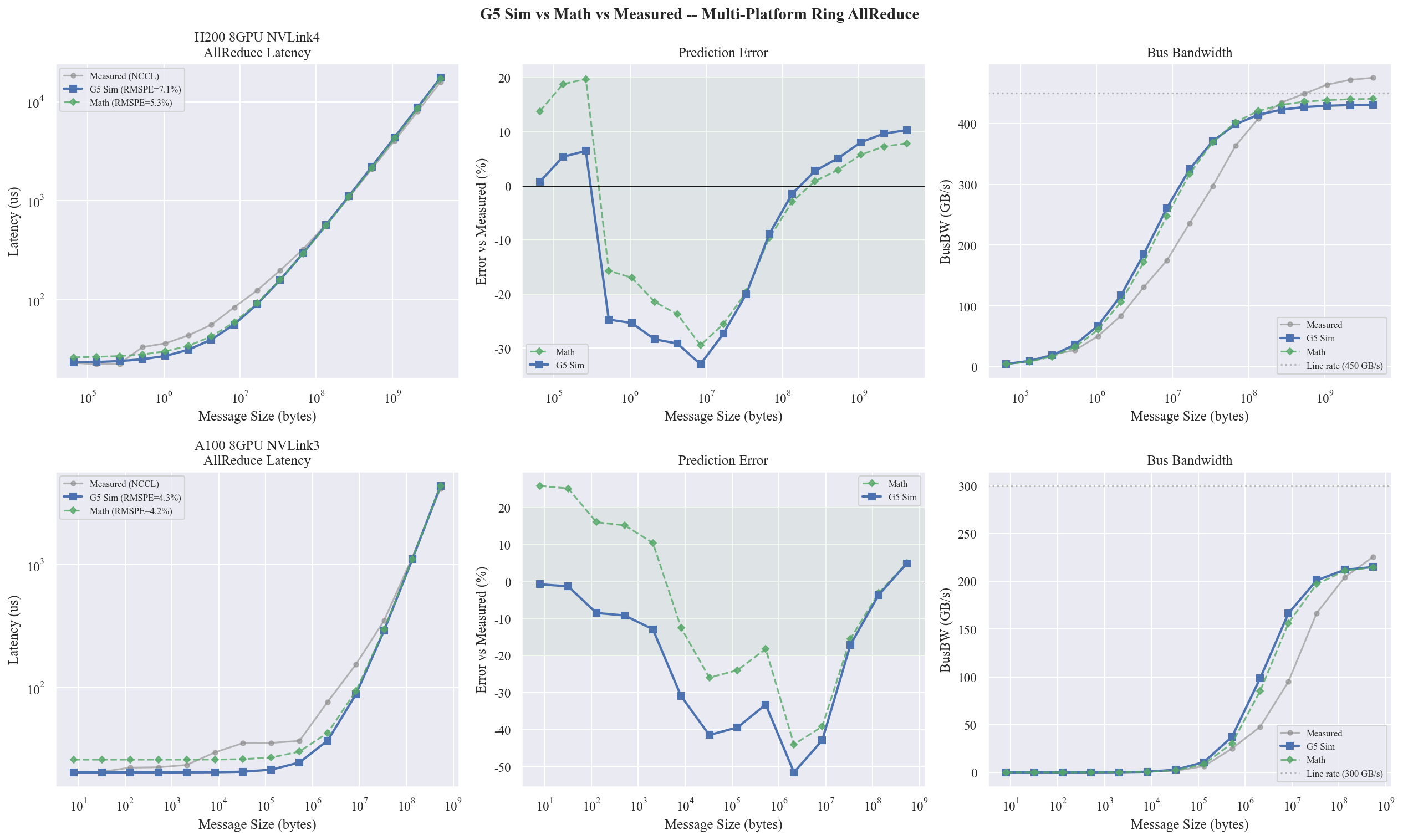
G5 仿真 vs Math 模型 vs 实测。上行 H200 NVLink4,下行 A100 NVLink3。三列分别为延迟、预测误差、BusBW。两种引擎的曲线几乎完全重合。
为什么 G5 与 Math 结果一致
在当前验证场景(单次 AllReduce、无拥塞、单层全连接 Ring)下,G5 仿真器的行为退化为:
$T_{\text{G5}} \approx \frac{\text{data\_bytes}}{\text{cdma\_bw} \times \text{efficiency}} + \text{startup} \times \text{steps} + \text{sw\_overhead}$
这与 alpha-beta 公式结构相同。原因:
- 无拥塞:8 芯片 Ring 每条链路同一时刻只有一个流,PAXI credit 和 RC Link 流控不构成瓶颈
- 无交换机:点对点直连,无 VOQ/iSLIP 调度延迟
- CDMA 稳态流水线:大消息分包传输稳态后,有效吞吐 = BW × efficiency ≈ $\beta \cdot u_r$
G5 真正的优势场景尚未验证:多流并发拥塞、交换机 ECMP 负载均衡、Go-Back-N 重传、DCQCN 拥塞控制——这些场景下 alpha-beta 的静态假设会失效,而 G5 能建模动态行为。
已知偏差:G5 在中间消息段(1~16 MB)偏快约 20-30%,原因是当前未建模 AllReduce 每步的 reduce 计算时间。
参考资料
| 资料 | 内容 |
|---|---|
| 互联技术调研 | 各互联代际规格、实测 BusBW 汇总 |
| SimAI NSDI'25 | 98.1% 端到端精度(含 ratio table 校准) |
| SimAI GitHub | NS-3 后端、ratio table、拓扑模板 |