NVSwitch 与 NVLS 超线速互联
NVSwitch 是 NVIDIA 专为 GPU 互联设计的高速交换芯片,解决了 NVLink 点对点直连在多 GPU 场景下扩展性不足的问题。从 NVSwitch Gen3(Hopper 时代)起,NVSwitch 内置了网内计算引擎,实现了 NVLS(NVLink SHARP)机制——数据在经过交换芯片时即完成规约,无需 GPU 多轮传递,从根本上突破了 Ring AllReduce 的带宽上限。
NVSwitch 代际演进
| 代际 | 发布年份 | 搭配 GPU | 端口数 | 单端口带宽(双向) | 总交换带宽 | NVLS 支持 |
|---|---|---|---|---|---|---|
| NVSwitch 1.0 | 2018 | V100 SXM3 | 18 | 50 GB/s × 2 | 900 GB/s | 否 |
| NVSwitch 2.0 | 2020 | A100 SXM4 | 36 | 50 GB/s × 2 | 1.6 TB/s | 否 |
| NVSwitch 3.0 | 2022 | H100 SXM5 | 64 | 50 GB/s × 2 | 3.2 TB/s | 是 |
| NVSwitch 4.0 | 2024 | B200 SXM6 | 72 | 100 GB/s × 2 | 7.2 TB/s | 是 |
NVSwitch 1.0/2.0 单端口速率对应 NVLink 2.0/3.0 的物理带宽。NVSwitch 3.0 端口数为 64,每端口使用 NVLink 4.0(50 GB/s 单向)。NVSwitch 4.0 端口数扩展到 72,搭配 NVLink 5.0 单端口速率翻倍(100 GB/s 单向),总带宽大幅提升以适配 NVL72 的 72 GPU 全连接需求。
NVSwitch 交换架构
NVSwitch 内部采用**全双工非阻塞交叉开关(Non-blocking Crossbar)**结构,每个端口独立缓冲,任意端口对之间可同时传输数据而不争用内部带宽。
与以太网交换机的本质区别:
| 特性 | NVSwitch | 以太网交换机 |
|---|---|---|
| 协议栈 | NVLink 原生协议,无 IP/MAC | 需处理以太网帧、IP 头、TCP/UDP |
| 交换延迟 | NVSwitch 3.0 约 100 ns | 通常 500 ns–2 µs(切入转发) |
| 流量控制 | 基于 flit 的硬件信用流控 | 基于软件的拥塞控制(ECMP、PFC) |
| 计算能力 | 内置归约引擎(NVLS) | 纯转发,无网内计算 |
| 寻址 | GPU ID 映射到物理端口 | MAC/IP 地址查表 |
NVSwitch 消除了协议栈开销,交换延迟约为以太网交换机的 1/10–1/20,是 NVLink 域内延迟能维持在亚微秒级的关键。
每个端口独立维护发送/接收缓冲区,基于硬件信用(credit-based flow control)在 flit 粒度进行背压,避免头阻塞(Head-of-Line blocking),保证交叉开关利用率。
NVL72 系统中的 NVSwitch 拓扑
NVL72 是 NVIDIA Blackwell 时代(2024 年)的旗舰单域互联系统,由 72 个 B200 GPU(来自 36 个 GB200 Superchip,每个 Superchip 含 2 颗 B200)和 18 个 NVSwitch 4.0(来自 9 个 Switch Tray,每 Tray 含 2 颗 NVSwitch 4.0)组成,通过 NVLink 5.0 全互联。
连接方式:每个 B200 GPU 通过 18 条 NVLink 5.0 链路分别连接到全部 18 个 NVSwitch 4.0(每个 NVSwitch 连 1 条),每颗 NVSwitch 的 72 个端口各连接 1 颗 B200 GPU(72 GPU × 18 links/GPU = 18 NVSwitch × 72 ports = 1296 总链路)。由 NVSwitch 完成全交叉交换,任意 GPU 对通信只经过 1 跳。
关键特性:
- 任意两个 GPU 之间通信只需经过 1 跳 NVSwitch(全连接,无需多跳路由)
- 每对 GPU 间可同时使用多条通路(通过多个 NVSwitch 并行),有效双向带宽可叠加
- 单个 GPU NVLink 带宽:18 条 NVLink 5.0 × 100 GB/s(每方向)= 1800 GB/s(单向聚合,NVLink 4.0 的 2 倍)
全局带宽上限:72 GPU × 1800 GB/s(单向) ÷ 2(收发各半)= 64.8 TB/s 聚合单向带宽。在带宽饱和场景(如全局 AllReduce),每个 GPU 的实际可用带宽受限于对外链路,而非 NVSwitch 内部带宽。
NVLS 机制原理
NVLS(NVLink SHARP)是 NVSwitch 3.0 起内置的**网内计算(In-Network Computing)**能力,允许在数据经过 NVSwitch 芯片时直接执行归约操作。
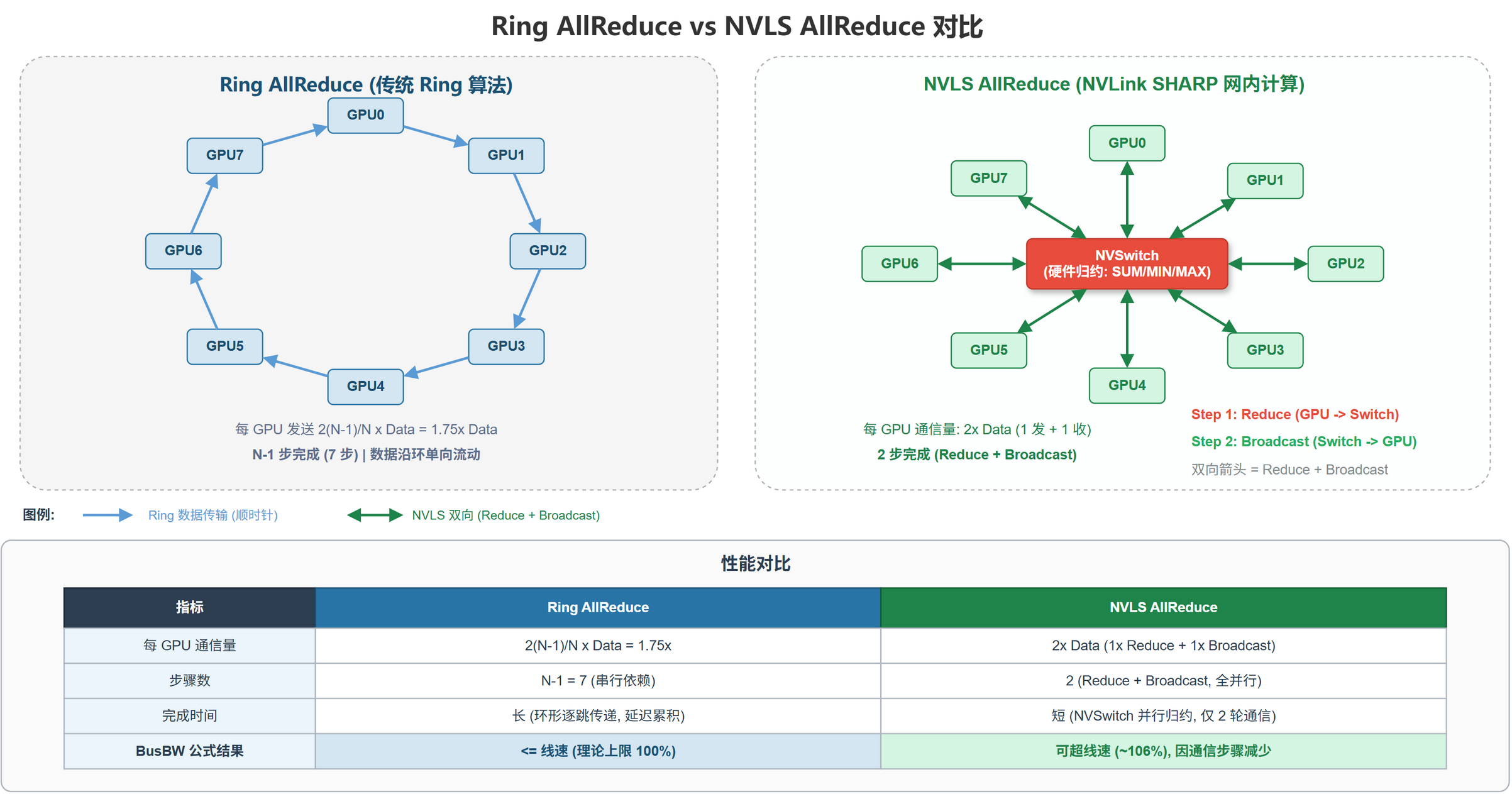
传统 Ring AllReduce 的数据路径:
每个 GPU 既是数据源,也是中继节点:
GPU₀ → GPU₁ → GPU₂ → ... → GPU_{N-1} → GPU₀(ReduceScatter)
GPU₀ → GPU₁ → GPU₂ → ... → GPU_{N-1} → GPU₀(AllGather)
每个 GPU 需执行 2(N-1) 次发送/接收
NVLS 的数据路径:
GPU₀ ─┐
GPU₁ ─┤
GPU₂ ─┤→ NVSwitch(硬件归约引擎)→ 广播结果给所有 GPU
... ─┤
GPU₇₁─┘
每个 GPU 只需 1 次发送 + 1 次接收
NVSwitch 内的归约引擎以流水线方式对各端口接收到的数据执行累加(支持 FP16/BF16/FP32/INT32 等数据类型),归约结果通过多播(Multicast)同时发送给所有参与 GPU。多播在交换芯片内部完成一次复制,无需 GPU 介入,避免了 Broadcast 阶段的带宽浪费。
与 InfiniBand SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)的对比:IB SHARP 的聚合节点(Aggregation Node)运行在交换机的协处理器上,受限于协处理器算力;NVLS 的归约引擎直接集成在 NVSwitch 数据路径中,吞吐量与链路带宽匹配,不成为瓶颈。
NVLS 对 AllReduce 性能的影响
延迟模型对比
Ring AllReduce($N$ 个 GPU,消息大小 $M$):
$T_{\text{Ring}} \approx 2(N-1)\alpha + \frac{2(N-1)}{N} \cdot \frac{M}{\beta}$
步数为 $2(N-1)$,随 $N$ 线性增长。
NVLS AllReduce(数据均在同一 NVSwitch 域内):
$T_{\text{NVLS}} \approx 2\alpha_{\text{sw}} + \frac{M}{\beta_{\text{NVLink}}}$
其中 $\alpha_{\text{sw}}$ 为 NVSwitch 处理延迟(约 100–200 ns),步数固定为 2(发送 + 接收),与 $N$ 无关。
带宽利用率对比
| 指标 | Ring AllReduce | NVLS AllReduce |
|---|---|---|
| 每 GPU 有效发送量 | $\frac{2(N-1)}{N}M \approx 2M$ | $M$(仅发送一次) |
| 带宽利用率 | $\frac{N-1}{N}$(接近但小于 1) | 接近 100%(受限于链路带宽) |
| 延迟步数 | $2(N-1)$ | 2 |
参考实测数据(H100 DGX,8 GPU NVLink 4.0,AllReduce on 1 GB):
- Ring AllReduce:约 394 GB/s
- 理论上限:$\frac{7}{8} \times 450 \approx 394$ GB/s(NVLink 4.0 单向 450 GB/s,$N=8$)
- 实测接近理论上限,与公式预测一致
- NVLS AllReduce:约 480 GB/s,超越 Ring 理论上限约 22%
- NVLS 不受 $(N-1)/N$ 系数约束,可将链路带宽全部用于有效数据传输
注:以上为 H100 NVLink 4.0(NVSwitch 3.0)时代数据,用于说明 NVLS 加速效果。B200 NVL72(NVSwitch 4.0,NVLink 5.0)的绝对带宽数字将按 ×2 比例提升,但 NVLS 的相对加速比保持一致。
使用限制
拓扑要求:
- 所有参与 GPU 必须在同一 NVSwitch 全连接域内(即所有 GPU 到任意 NVSwitch 只需 1 跳)
- NVL8(单节点 8 GPU)和 NVL72(72 GPU 机箱)均满足此条件
- 多节点跨 InfiniBand/Ethernet 的 GPU 组无法使用 NVLS,仍回退到 Ring AllReduce
原语支持:
- 当前 NVLS 仅支持 AllReduce 原语(Send+Reduce+Multicast)
- 不支持独立的 AllGather 或 ReduceScatter(这两个原语的 NVLS 加速需要更复杂的多播树设计,截至 NVSwitch 3.0 尚未实现)
软件要求:
- 需要 NCCL 2.17 或更高版本(含 NVLS 自动检测逻辑)
- NCCL 在消息大小 > 256 KB 时自动启用 NVLS;小消息延迟由启动开销主导,Ring 与 NVLS 差距不显著
数据类型:
- 支持 FP32、FP16、BF16、INT32 的硬件归约
- 不支持 FP8(归约精度问题);FP8 场景需在 GPU 端完成类型转换后再触发 NVLS
参考资料
NVSwitch 3.0 / H100 时代:
- NVIDIA H100 SXM Architecture White Paper(NVIDIA, 2022)
- NVIDIA NVSwitch 3.0 Technical Brief(NVIDIA, 2022)
- Hot Chips 2022: NVLink 4 and NVSwitch 3(NVIDIA, 2022)
- NCCL 2.17 Release Notes: NVLS Support(NVIDIA)
NVSwitch 4.0 / B200 / GB200 NVL72:
- NVIDIA GB200 NVL72 Product Page(NVIDIA, 2024)
- NVIDIA Blackwell Architecture Technical Overview(NVIDIA, 2024)
- GTC 2024: NVIDIA Blackwell Platform(NVIDIA, 2024)
- Scaling Deep Learning Training with NVLink(NVIDIA Developer Blog)