Tier6+大模型部署推理建模平台
type: 修订记录
| 版本号 | 修订日期 | 作者 | 修订内容 |
| ------ | ---------- | ---------- | ---------------------------------------------------------------- |
| 1.0 | 2026.02.27 | 李想 | 首次制作 |
总则
目的
- 本文档为 Tier6+大模型部署推理建模平台(以下简称"平台")的标准操作检查规程。旨在为平台使用者提供完整的操作指南,使读者在无其他参考资料的情况下,能够独立完成从环境搭建到评估结果解读的全部操作流程,确保各项功能正确使用,评估结果可信、可复现。
适用范围
- 适用于使用本平台进行以下工作的工程师和研究人员:
- 配置 LLM 推理部署拓扑(芯片、互联、层级结构)
- 执行性能仿真与成本评估(Prefill/Decode 阶段)
- 分析和对比不同部署方案(并行策略、芯片数量)
- 管理实验数据(导入/导出/对比)
名词定义
-
平台涉及的主要术语和缩写定义如下:
缩写/术语 全称 含义 TP Tensor Parallelism 张量并行,将单个算子拆分到多个芯片上并行计算 PP Pipeline Parallelism 流水线并行,将模型不同层分配到不同芯片 DP Data Parallelism 数据并行,不同芯片处理不同批次的数据 EP Expert Parallelism 专家并行,MoE 模型中将不同专家分配到不同芯片 SP Sequence Parallelism 序列并行,将输入序列拆分到多个芯片处理 MoE Mixture of Experts 混合专家模型,每个 token 仅激活部分专家 MLA Multi-head Latent Attention 多头潜在注意力,DeepSeek 系列使用的 KV 缓存压缩技术 TPS Tokens Per Second 每秒输出 token 数,衡量推理吞吐量 MFU Model FLOPS Utilization 模型算力利用率,实际使用算力 / 峰值算力 MBU Memory Bandwidth Utilization 内存带宽利用率,实际带宽使用 / 峰值带宽 Prefill Prefill Phase 预填充阶段,处理输入 prompt 的阶段 Decode Decode Phase 解码阶段,逐 token 生成输出的阶段 AllReduce All-Reduce 集合通信操作,所有节点参与归约并广播结果 AllToAll All-to-All 集合通信操作,所有节点间交换数据(用于 MoE 专家路由) Benchmark Benchmark Configuration 基准测试配置,定义模型 + 推理参数的组合 Topology Network Topology 网络拓扑,描述芯片间的物理连接和层级结构 Gantt Chart Gantt Chart 甘特图,展示仿真过程中各阶段的时间线 Roofline Roofline Model 屋顶线模型,分析算力与带宽的瓶颈关系
平台使用全流程总览
- 完整的评估流程分为以下步骤:
- 环境搭建:安装依赖、启动前后端服务(首次使用时执行)。
- 配置互联拓扑:在「互联拓扑」页面配置目标硬件的层级结构、芯片型号和互联参数。
- 配置评估任务:在「部署分析」页面选择模型预设、推理参数、并行策略,设置分析选项。
- 执行评估:提交评估任务,等待仿真计算完成。
- 查看与分析结果:在分析结果区域或「结果管理」页面查看 KPI 指标与可视化图表,对比多方案。
- 导出数据:将实验结果导出为 JSON 文件留存或在团队间共享。
环境搭建
系统要求
-
平台的系统最低运行要求如下:
项目 最低要求 操作系统 Windows 10/11、Linux (Ubuntu 20.04+) Python 3.10+ Node.js 18+ 包管理器 pip(Python)、pnpm(前端) 浏览器 Chrome 90+ / Edge 90+(推荐使用 Chrome) 端口 3100(前端)、8003(后端)需可用 -
注意:启动前请确认 3100 和 8003 端口未被其他程序占用。若端口冲突,需修改
frontend/.env中的VITE_API_PORT配置项,并相应修改后端启动参数。
安装步骤
-
后端依赖安装
-
进入项目根目录,安装 Python 依赖:
pip install -r requirements.txt -
安装成功验证:所有依赖包无 ERROR 完成安装(WARNING 可忽略)。若出现版本冲突,建议在 Python 虚拟环境(venv 或 conda)中安装。
-
-
前端依赖安装
-
进入前端目录,安装 Node.js 依赖:
cd frontend
pnpm install -
安装成功验证:
node_modules目录生成,无 ERR 错误输出。 -
注意:前端使用 pnpm 而非 npm 或 yarn。若未安装 pnpm,先执行
npm install -g pnpm安装。
-
启动平台
-
首次启动(含依赖安装)
-
执行以下命令:
# Linux/Mac
./start.sh --setup
# Windows
start.bat --setup -
启动脚本执行流程:
- 检查后端 Python 依赖(
requirements.txt),若未安装则自动安装。 - 启动后端服务(FastAPI + Uvicorn,端口 8003)。
- 检查前端 Node.js 依赖,若未安装则自动执行
pnpm install。 - 启动前端开发服务器(Vite,端口 3100)。
- 自动在默认浏览器打开
http://localhost:3100。
- 检查后端 Python 依赖(
-
-
日常启动
-
执行以下命令:
# Linux/Mac
./start.sh
# Windows
start.bat -
启动后同时运行后端(8003 端口)和前端(3100 端口)。
-
关闭服务:关闭后端和前端各自的命令行窗口即可停止服务。
-
启动验证
- 启动完成后,按以下步骤验证平台正常运行:
- 浏览器访问
http://localhost:3100,应看到平台概览页面(Dashboard)。 - 左侧导航栏应显示完整菜单:概览、互联拓扑、部署分析、结果管理、知识网络。
- 浏览器访问
http://localhost:8003/docs,应显示 FastAPI 自动生成的 Swagger API 文档页面,API 端点列表非空(说明后端路由注册正常)。 - 点击「部署分析」,左侧 Benchmark 配置卡片中的预设下拉框应能成功加载预设列表(非空)。
- 浏览器访问
- 若步骤 4 中预设列表为空或加载失败,说明后端服务未正常启动,检查后端命令行窗口的错误日志。
平台概述
界面布局
-
-
平台采用左侧导航 + 右侧主内容区的双栏布局:
- 左侧导航栏:固定在页面左侧,包含 5 个功能模块入口。支持折叠/展开操作,展开宽度 180px,折叠宽度 64px。折叠时,鼠标悬停菜单项会显示 tooltip 提示。导航栏底部显示折叠控制按钮和当前版本号。
- 右侧内容区:根据当前选中的功能模块显示对应页面的完整内容。
功能模块导航
-
左侧导航栏包含以下 5 个功能模块:
序号 菜单项 功能说明 1 概览 系统总览,显示快速操作入口和最近任务列表 2 互联拓扑 3D 拓扑可视化配置,编辑芯片连接和层级结构 3 部署分析 LLM 部署评估核心页面,配置模型/拓扑/并行策略 4 结果管理 实验与任务结果的查看、对比、导入导出管理 5 知识网络 分布式计算概念的交互式知识图谱 -
点击任一菜单项切换到对应页面。
概览页面(Dashboard)
-
-
概览页面提供 4 个快速操作卡片,点击卡片可快速跳转到对应功能模块:
- 互联拓扑配置
- 部署分析
- 结果管理
- 知识网络
-
页面下方的「最近任务」区域显示最近 5 条评估任务记录,包含任务名称、状态和创建时间,可快速了解当前评估进展。
互联拓扑配置
页面布局
-
-
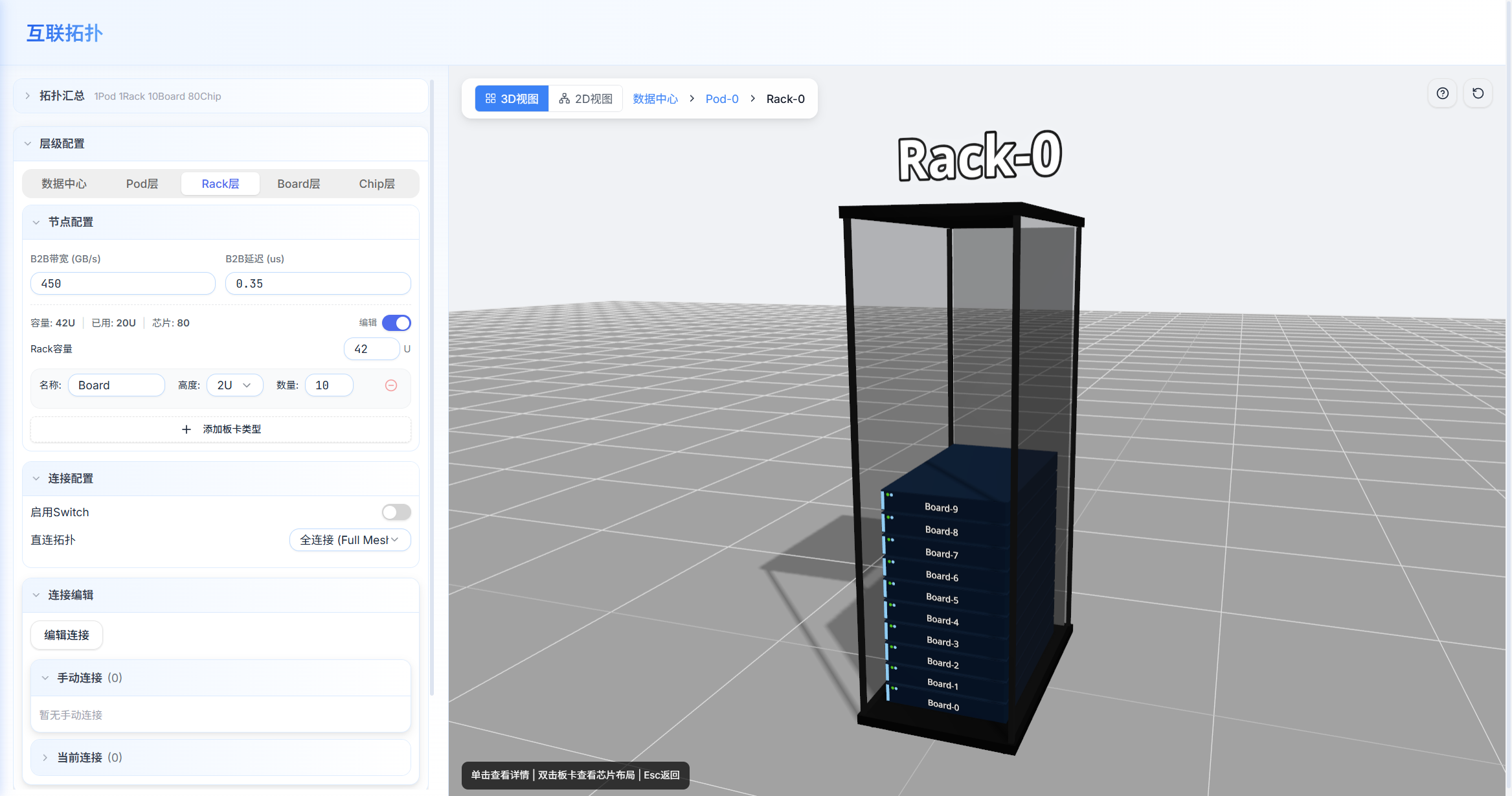
页面分为左右两栏,中间可拖动分隔条调整宽度比例:
- 左栏(配置面板):拓扑层级结构配置、芯片硬件参数编辑、互联参数配置。
- 右栏(可视化区域):支持两种视图模式,通过右上角按钮切换:
- 3D 场景视图:使用 Three.js 渲染的 3D 立体拓扑结构,直观展示层级关系。
- 2D 拓扑图:基于力导向布局的 2D 连接关系图,展示芯片节点间的连接关系。
拓扑层级结构
-
平台采用 5 级拓扑层级,从外到内依次为:
层级 名称 说明 1 Pod 集群级别,包含多个 Rack 2 Rack 机柜级别,包含多个 Board 3 Board 节点/服务器级别,包含多个 Chip 4 Chip 加速器级别,计算的基本单元 5 Die 可选,芯片内 chiplet 架构(Die-to-Die 互联) -
不同的 Rack、Board 可以有不同的芯片配置(异构支持),总芯片数为各层级节点实际挂载芯片数的求和。
拓扑配置操作
-
选择预设拓扑
- 在配置面板顶部找到拓扑选择器下拉框。
- 点击下拉框,从列表中选择预设拓扑模板,如 P1-R1-B1-C8(1 Pod、1 Rack、1 Board、8 Chip)。
- 预设加载后,层级参数和芯片配置自动填充,3D 视图自动渲染对应的拓扑结构。
- 拓扑命名规则:P{Pod 数}-R{Rack 数}-B{Board 数}-C{Chip 数}。
-
自定义拓扑层级参数
- 在配置面板中逐级填写拓扑结构参数:
- Pod 配置:在"Pod 数量"输入框中填写 pod_count(Pod 总数)。
- Rack 配置:填写 racks_per_pod(每个 Pod 中的 Rack 数量)。
- Board 配置:填写每个 Rack 中的 Board 数量,以及每个 Board 上挂载的芯片类型和数量。
- Chip 配置:从芯片类型下拉框中选择芯片型号(如 SG2262、H100),填写每个 Board 上该类型芯片的数量。
- 修改层级参数后,3D 视图实时更新以反映新的拓扑结构。
- 在配置面板中逐级填写拓扑结构参数:
-
互联参数配置
-
在配置面板的互联参数区域,配置各层级间的连接带宽和延迟:
互联层级 标识 典型场景 示例参数 芯片间 c2c Die-to-Die(同封装内) 448 GB/s, 0.2 us 板间 b2b 同机柜内跨板(NVLink 等) 400 GB/s, 2.0 us 柜间 r2r 同 Pod 内跨柜(InfiniBand 等) 400 GB/s, 3.0 us Pod 间 p2p 跨 Pod(高速以太网) 400 GB/s, 5.0 us -
还可配置集合通信算法参数:
参数 说明 可选值 AllReduce 算法 TP 组内的 AllReduce 集合通信算法 ring / double_binary_tree / halving_doubling / reduce_broadcast AllToAll 算法 MoE 专家路由的 AllToAll 集合通信算法 pairwise / ring / bruck 网络效率系数 实际可用带宽相对标称带宽的比例(0-1) 0 到 1 之间的小数,典型值 0.85 计算-通信重叠 是否允许通信与计算并行执行 开/关
-
-
拓扑配置保存
- 当前的拓扑配置(层级参数、芯片型号、互联参数)会自动保存到浏览器本地存储(localStorage)。关闭浏览器后重新打开,配置会自动恢复。
- 注意:浏览器本地存储在清除浏览器数据后会丢失。如需长期保存某个拓扑配置,建议在「部署分析」页面提交评估后,在「结果管理」中导出实验数据——导出文件包含完整的拓扑配置快照。
芯片硬件参数编辑
-
在配置面板的芯片配置区域,可查看和编辑芯片的详细硬件参数:
参数 说明 compute_tflops_fp8 FP8 精度下的峰值算力(TFLOPS) compute_tflops_bf16 BF16 精度下的峰值算力(TFLOPS) memory_capacity_gb 显存总容量(GB) memory_bandwidth_gbps 显存带宽(GB/s) memory_bandwidth_utilization 显存带宽实测利用率上限(0-1) lmem_capacity_mb 片上 SRAM 总容量(MB) sram_size_kb 单个计算核的 SRAM 大小(KB) cube_m / cube_k / cube_n 矩阵计算单元(Cube Unit)的三个维度尺寸参数 lane_num 并行计算通道数 compute_dma_overlap_rate 计算与 DMA 数据传输的重叠率(0-1) -
修改参数后,下次提交评估时将使用修改后的参数。若参数与预设不同,配置名称旁会出现橙色修改标记。
3D 可视化操作
-
-
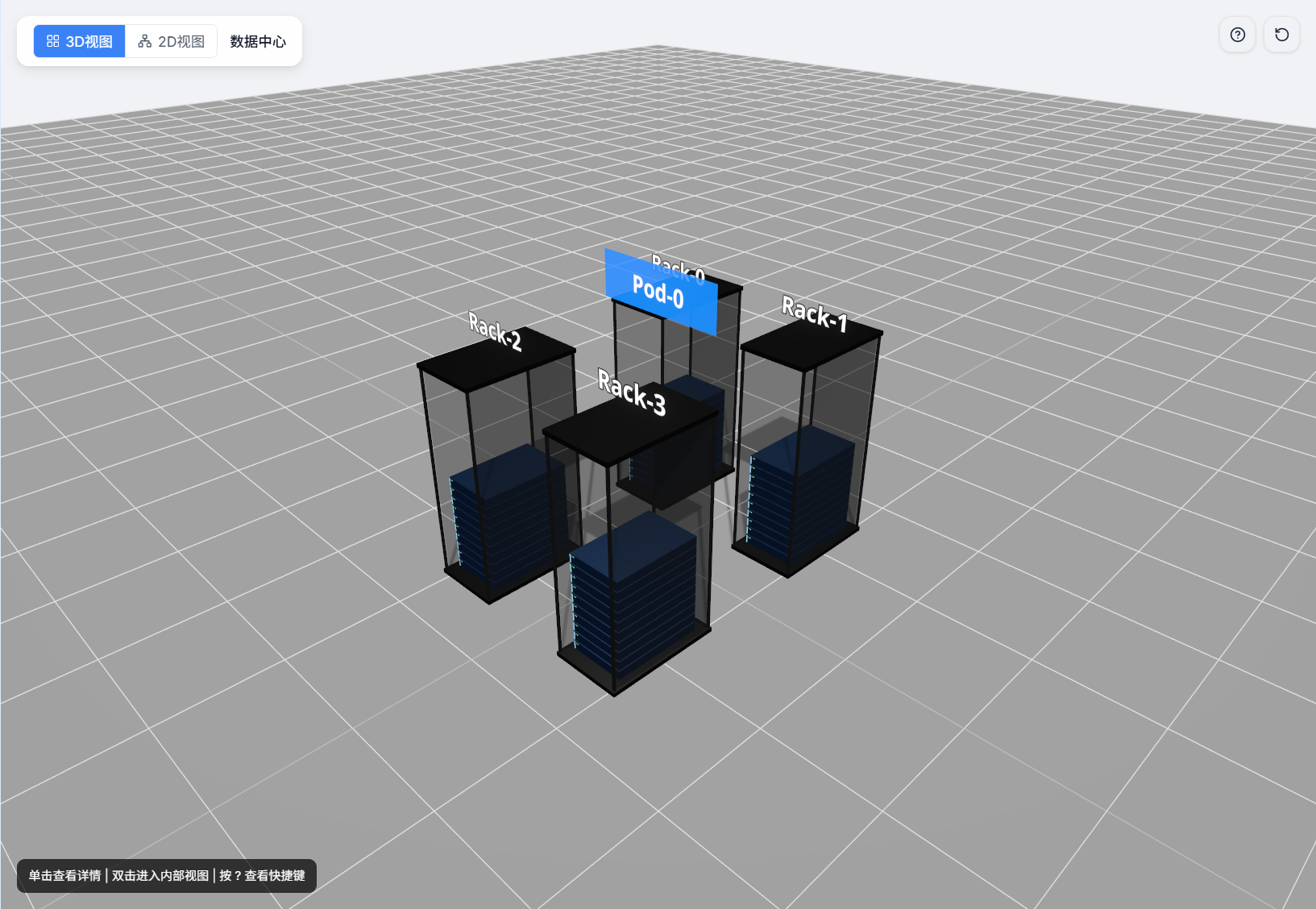
支持的交互操作:
操作 方式 效果 旋转视角 鼠标左键拖动 旋转整个 3D 场景 缩放 鼠标滚轮 放大/缩小视图 平移 鼠标右键拖动 平移视图位置 选择节点 单击节点 高亮该节点,右侧显示节点详情 进入子层级 双击节点 深入到该节点的内部子层级视图 返回上级 按 ESC 键 返回上一层级视图 -
颜色编码:Pod(蓝色)、Rack(绿色)、Board(黄色)、Chip(红色)。
-
页面顶部的面包屑导航显示当前所在层级路径,可点击各层级名称快速跳转到对应层级。
2D 拓扑图操作
- 切换到 2D 视图后,以力导向图展示芯片节点间的连接关系:
- 鼠标拖拽:平移画布视图。
- 鼠标滚轮:缩放视图。
- 单击节点:选中节点并高亮其所有连接边。
- 2D 视图适合查看芯片间的连接拓扑关系,以及并行组的分配情况(不同颜色节点代表不同并行组)。
部署分析
页面概述与使用流程
-
-
部署分析是平台的核心功能页面,用于配置 LLM 推理部署方案并执行性能评估。标准使用流程:
- 选择或配置 Benchmark(模型 + 推理参数)。
- 确认或修改拓扑与芯片硬件参数。
- 配置并行策略(手动/自动搜索/参数扫描三选一)。
- 配置分析选项(任务名称、评估阶段、优化开关)。
- 点击「运行分析」执行评估。
- 评估完成后,前往「结果管理」页面查看详细分析图表。
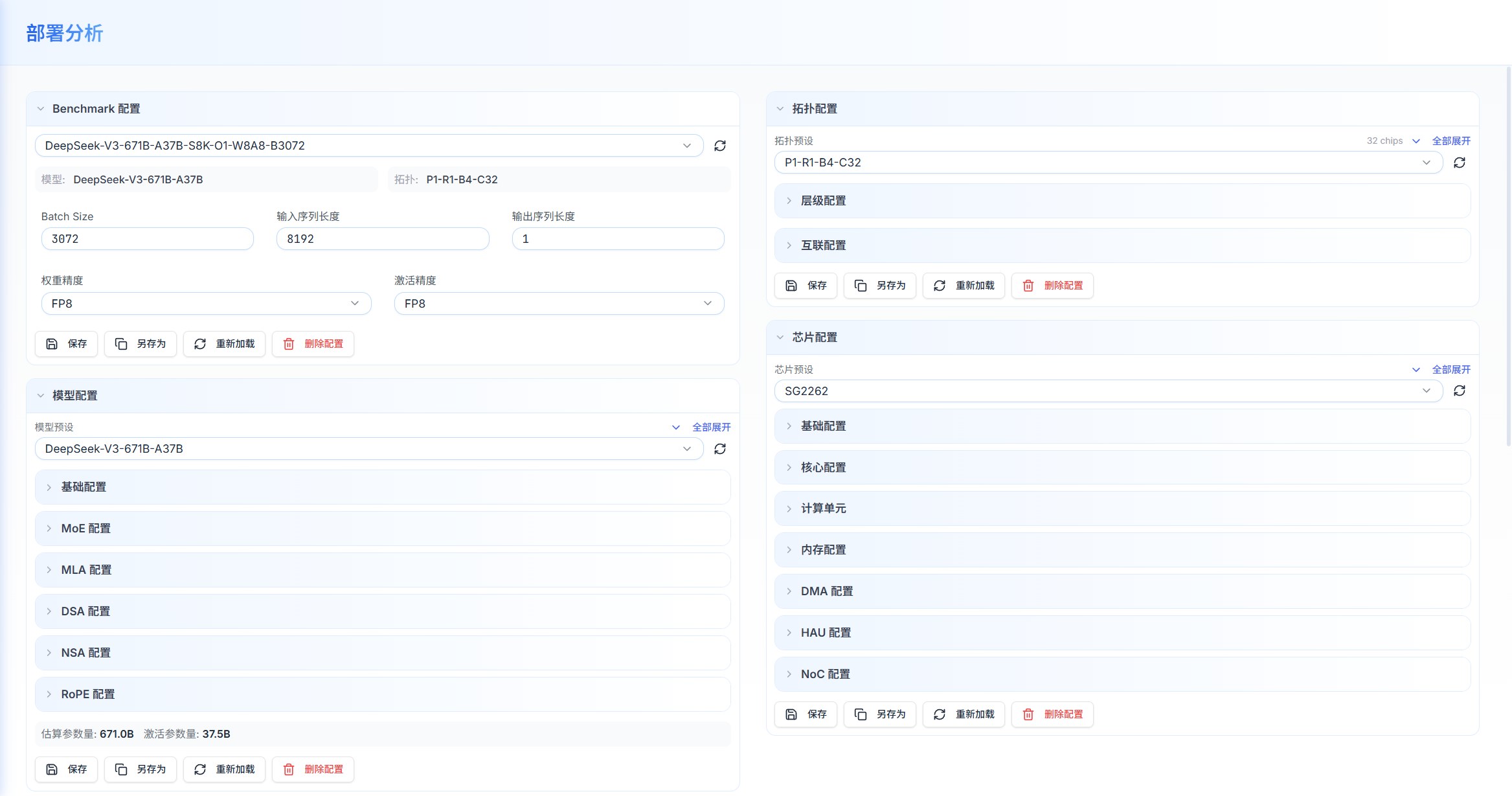
Benchmark 配置
-
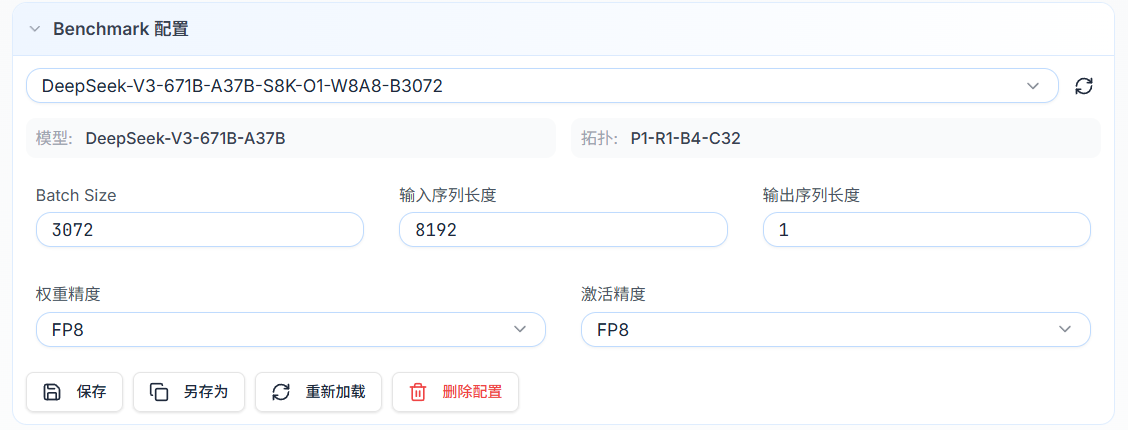
-
Benchmark 是"模型 + 推理参数"的组合配置,完整描述一个推理评估场景。
-
选择 Benchmark 预设
- 展开左栏的「Benchmark 配置」卡片。
- 点击预设下拉框,从列表中选择预设(如"DeepSeek-V3 + 8 chips")。
- 预设加载后,以下字段自动填充:
- 模型选择(Model)
- 拓扑选择(Topology)
- 推理参数(Batch Size、Input/Output Seq Length 等)
- 预设名称旁的刷新图标可重新拉取预设列表(服务端新增预设后使用)。
- 注意:选择 Benchmark 预设会同时更新模型和拓扑配置。若之前手动修改过参数,加载新预设后修改会被覆盖。
-
推理参数配置
-
在 Benchmark 配置卡片中直接编辑以下推理参数:
参数 说明 典型值 Batch Size 并发请求数(批处理大小) 1(实时)、32(离线) Input Seq Length 输入序列长度(tokens) 1024、4096 Output Seq Length 输出序列长度(tokens) 256、2048 Weight Precision 权重存储精度 BF16、FP8、INT8、INT4 Activation Precision 激活值计算精度 BF16、FP16、FP8 -
修改任意参数后,Benchmark 名称旁会出现橙色修改标记,提示当前配置与预设不同。
-
模型配置
-
选择模型预设
- 展开左栏的「模型配置」卡片。
- 点击模型选择器下拉框,选择预设模型,例如:
- DeepSeek-V3:671B MoE 模型,含 MLA 注意力机制,256 专家,8 专家/token
- DeepSeek-R1:DeepSeek R1 系列
- Qwen3-235B:Qwen3 235B 混合专家模型
- Qwen2.5-72B:Qwen 2.5 72B 稠密模型
- 模型参数自动填充,按类别在编辑器中分组显示。
-
基础结构参数(所有模型)
参数 说明 hidden_size 隐藏层维度 num_layers Transformer 层数 num_attention_heads 注意力头数 vocab_size 词表大小 intermediate_size FFN 中间层维度 -
MLA 参数(仅 DeepSeek 系列,mla.enabled: true 时显示)
- MLA 技术通过低秩矩阵分解压缩 KV Cache,可减少 5-8 倍 KV Cache 内存占用,是 DeepSeek 系列在长上下文场景下的关键优化。
参数 说明 kv_lora_rank KV 压缩秩(越小 KV Cache 内存越小) q_lora_rank Query LoRA 秩 qk_rope_dim RoPE 位置编码维度 v_head_dim Value 头维度 -
MoE 参数(仅混合专家模型,moe.enabled: true 时显示)
参数 说明 num_experts 专家总数 num_shared_experts 共享专家数(每个 token 都激活) experts_per_token 每个 token 激活的路由专家数 router_topk_policy 路由策略(greedy = 贪心选 Top-K 专家)
拓扑与硬件配置
- 在左栏的拓扑配置区域,从拓扑选择器选择预设拓扑;或使用「互联拓扑」页面中已配置好的当前拓扑(两处共享同一套配置)。
- 如需微调硬件参数,直接在拓扑卡片的芯片参数区域修改对应字段。
- 配置集合通信参数(AllReduce 算法、AllToAll 算法、网络效率系数、计算-通信重叠)。
- 注意:「部署分析」页面中的拓扑选择器与「互联拓扑」页面共用同一套拓扑数据,在任意一个页面修改后,另一页面同步更新。
并行策略配置
-
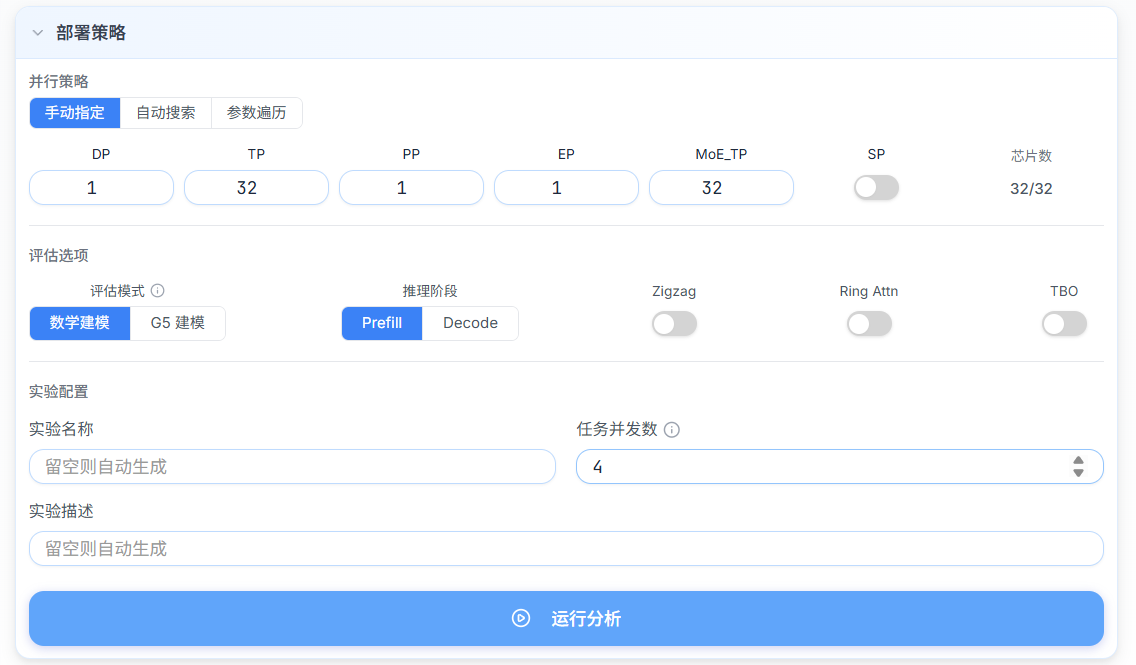
-
平台支持三种并行策略配置模式,在并行策略卡片顶部通过单选按钮切换模式。
-
手动模式(Manual)
-
手动指定各维度并行度,适用于验证特定并行方案。可配置的并行度参数:
参数 说明 DP 数据并行度(Data Parallelism) TP 张量并行度(Tensor Parallelism) PP 流水线并行度(Pipeline Parallelism) EP 专家并行度(Expert Parallelism,仅 MoE 模型) SP 序列并行度(Sequence Parallelism) MoE_TP MoE 层张量并行度(仅 MoE 模型) -
并行度约束:DP x TP x PP = 总芯片数。页面实时校验乘积是否等于可用芯片总数:
- 校验通过:输入框无异常样式,「运行分析」按钮可点击。
- 校验失败:输入框显示红色提示,「运行分析」按钮置灰,无法提交。
-
示例:拓扑为 P1-R1-B1-C8(共 8 芯片),设置 DP=2, TP=4, PP=1,则 2x4x1=8,校验通过。
-
-
自动搜索模式(Auto-search)
- 系统自动穷举或启发式搜索最优并行策略,适用于不确定最优配置的场景:
- 切换到「自动搜索」模式,可配置搜索约束(最大迭代次数、最大搜索时间等)。
- 点击「运行分析」,系统分两阶段执行:第一阶段生成所有满足约束条件的合法并行策略候选组合;第二阶段对每个候选方案独立执行评估,记录性能指标。
- 搜索过程实时展示进度(完成百分比、当前正在评估的方案)。
- 可在搜索过程中随时点击「取消」中止。
- 搜索完成后展示 Top-K 最优方案的排序和对比。
- 注意:搜索规模随芯片数量呈指数增长。芯片数较多(如 64 片以上)时,建议设置合理的最大迭代次数或时间约束,避免搜索时间过长。
- 系统自动穷举或启发式搜索最优并行策略,适用于不确定最优配置的场景:
-
参数遍历模式(Parameter Sweep)
- 对指定参数进行多值扫描,批量评估所有组合,适用于分析某参数对性能的影响规律:
- 切换到「参数遍历」模式。
- 选择要扫描的参数(如 batch_size、TP 等),可多选。
- 为每个参数配置扫描范围:起始值(扫描的最小值)、结束值(扫描的最大值)、步长(每步的递增量)。
- 可配置参数绑定组:同一绑定组内的参数同步变化;不同绑定组间做笛卡尔积展开。
- 页面底部显示总组合数,及预计提交的任务数量。
- 点击「运行分析」,系统批量提交所有参数组合的评估任务。
- 示例:扫描 batch_size(起始 1、结束 8、步长 1,共 8 个值),共提交 8 个评估任务。扫描 batch_size(4 个值)和 TP(3 个值),笛卡尔积共 4x3=12 个任务。
- 注意:参数扫描的所有结果自动归档到同一个实验下,方便在「结果管理」页面的参数敏感性分析中统一对比。
- 对指定参数进行多值扫描,批量评估所有组合,适用于分析某参数对性能的影响规律:
分析配置
-
在分析配置卡片中设置评估选项:
参数 说明 任务名称 本次评估的名称,用于在结果管理中识别(建议填写有意义的描述) 任务描述 可选,详细说明本次评估的目的或配置重点 最大并发数 同时并行执行的评估任务数(默认 4,可根据机器 CPU 核数调整) 评估阶段 勾选要评估的阶段:Prefill(预填充)、Decode(解码) Zigzag Reorder Prefill 阶段序列重排优化开关,启用后减少 AllToAll 通信量 Ring Attention TP > 1 时的 Ring Attention 优化开关,减少 Attention 通信开销 TBO MoE 模型的传输/带宽重叠优化(Transfer-Bandwidth Overlap) 评估模式 Math Mode(数学建模),基于解析公式估算推理时间 -
评估阶段说明
- Prefill:计算处理 prompt(输入序列)的时间,结果反映首 token 延迟(TTFT)。
- Decode:计算逐 token 生成的时间,结果反映吞吐量(TPS)和单 token 延迟(TPOT)。
- 通常两个阶段均需勾选,以获得完整的性能评估数据。
-
Math Mode 说明
- 基于解析公式对推理过程进行建模。将推理过程分解为计算(Compute)、内存访问(Memory)、通信(Communication)三类操作,使用 Roofline 模型和 alpha-beta 通信模型计算各阶段的理论执行时间,计算速度快,适用于快速方案评估和大规模参数扫描。
执行评估
- 确认所有配置(Benchmark、模型、拓扑、并行策略、分析配置)均已设置完毕,点击页面底部的「运行分析」按钮。
- 评估执行期间,右栏显示实时进度信息:
- 进度条和完成百分比
- 当前执行阶段描述(如"正在评估 Prefill 阶段...")
- 「取消」按钮(可随时中止当前评估)
- 评估完成后,结果保存到数据库,可在「结果管理」页面的对应实验下查看详细分析。
- 各模式的提交行为:
- 手动模式:提交单个评估任务,通常在 30 秒内完成。
- 自动搜索模式:提交搜索任务,系统内部迭代评估多个候选方案,耗时与搜索空间正相关。
- 参数扫描模式:提交多个独立评估任务(数量 = 参数组合数),并发执行(受最大并发数限制)。
结果管理
页面概述
-
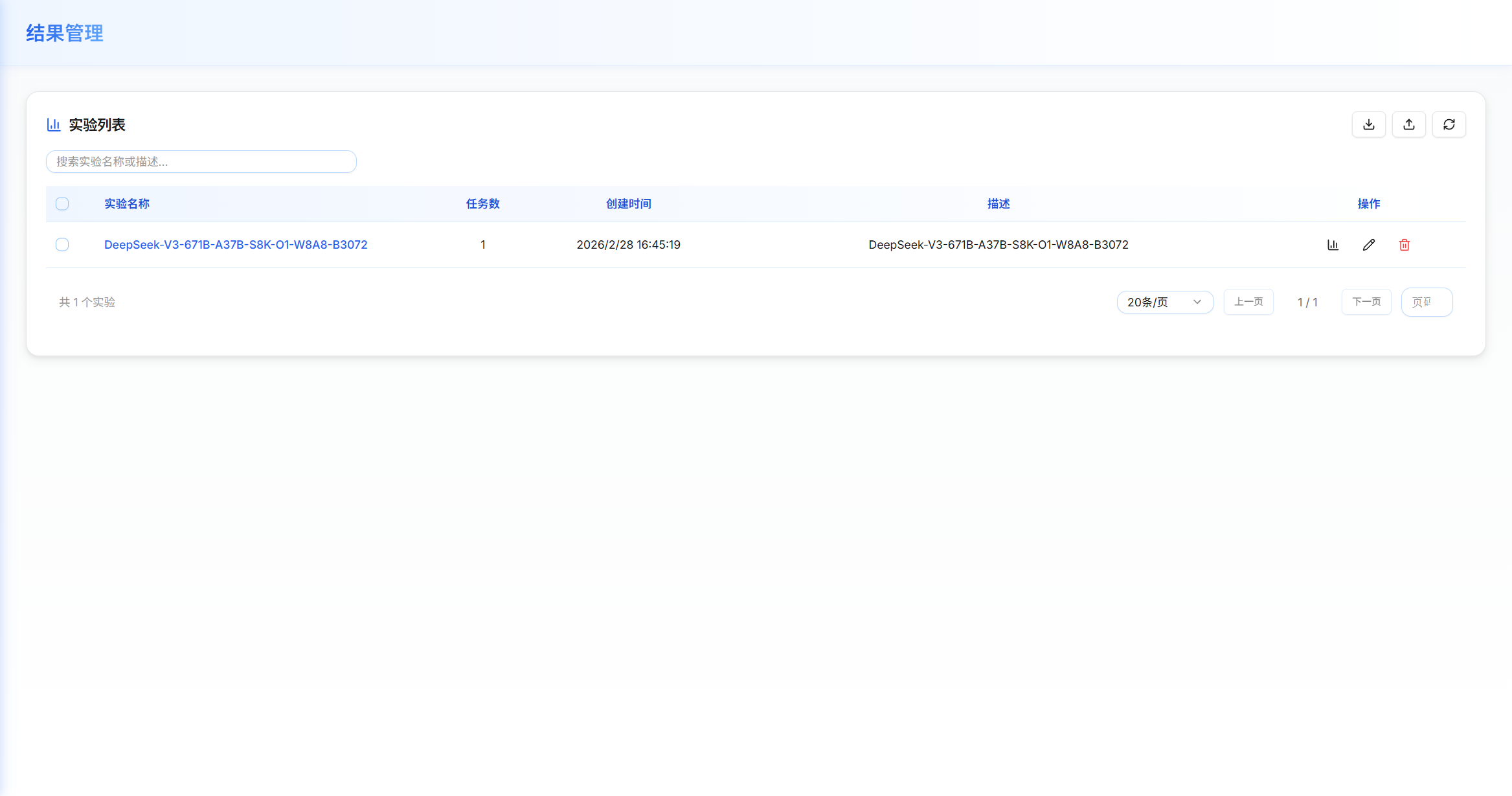
-
结果管理页面用于查看、分析和管理所有评估实验的结果。页面支持三级视图导航:
- 实验列表视图:显示所有实验的概览表格。
- 实验详情视图:显示某实验下所有评估任务的数据表格。
- 任务分析视图:显示某个具体任务的完整图表分析。
-
顶部面包屑导航显示当前所在层级(实验列表 / 实验详情 / 任务分析),可点击跳转。
实验列表视图
-
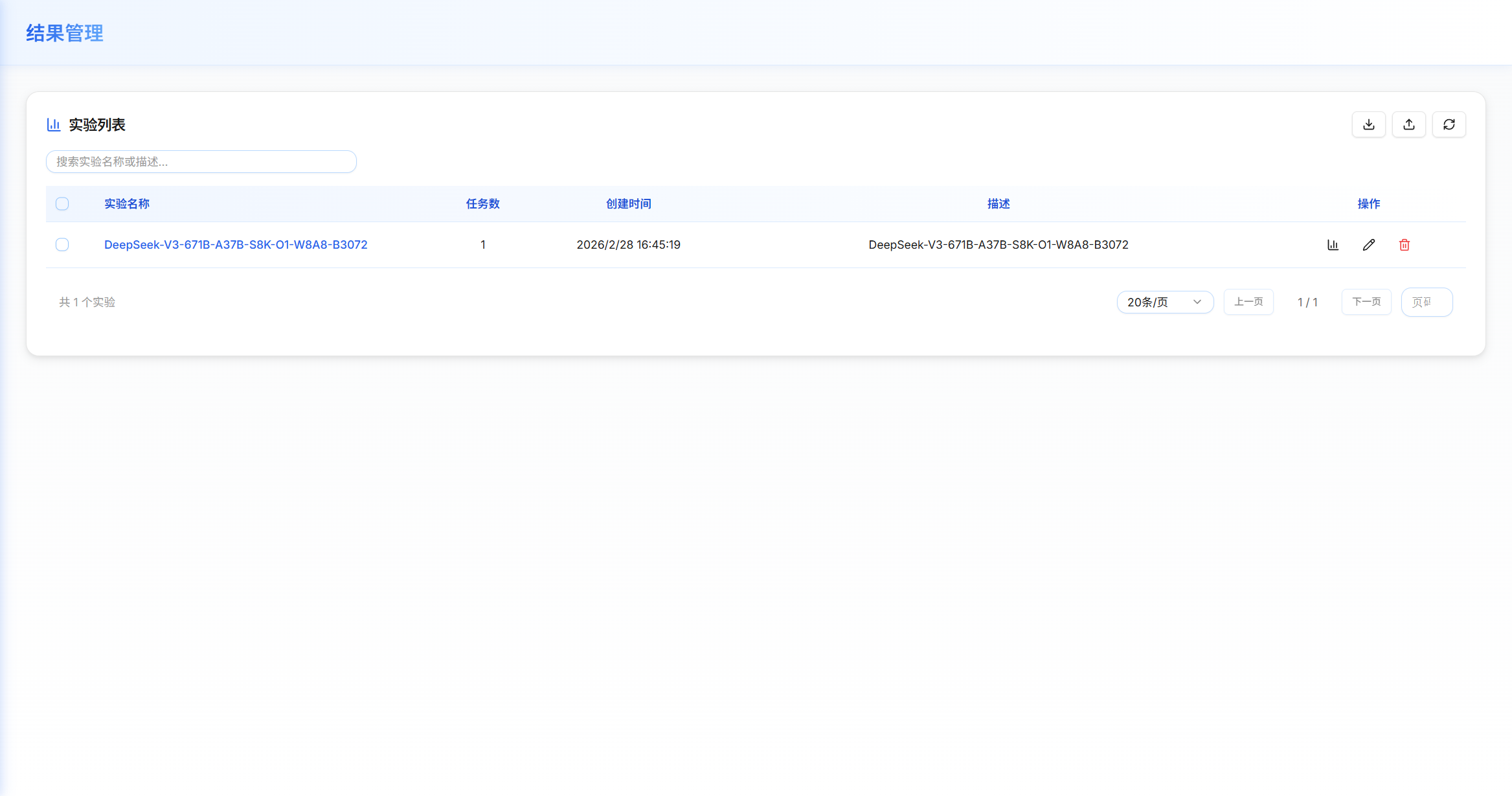
实验列表显示
-
-
实验列表以表格形式展示所有实验:
列 说明 选择框 用于批量操作的复选框 实验名称 实验的标识名称,点击进入该实验的详情页 描述 实验的描述信息 创建时间 实验创建的时间戳 任务数 该实验包含的评估任务数量 操作 查看详情图标、删除图标 -
支持分页,可在 10/20/50 条/页之间切换。
-
-
内联编辑实验元数据
- 在实验列表中,双击某实验的「名称」或「描述」字段,进入编辑模式(字段变为输入框)。
- 修改内容。
- 点击字段旁的保存图标(或按 Enter 键)确认保存;点击取消图标(或按 Esc 键)放弃修改。
- 修改成功后,列表中立即显示新内容,刷新页面后仍保持(已持久化到数据库)。
- 注意:内联编辑仅修改实验的元数据(名称、描述),不影响实验下的任务数据和评估结果。
-
批量操作
- 勾选需要操作的实验(单击行左侧复选框,或单击表头复选框全选当前页所有实验)。
- 工具栏显示「已选 N 个实验」,出现批量操作按钮。
- 点击「批量删除」,在弹出的确认对话框中确认,选中实验及其所有任务结果将被永久删除。
- 注意:删除操作不可恢复。批量删除前建议先导出需要保留的实验数据(见导入与导出章节)。
实验详情视图
-
点击实验名称进入实验详情视图,包含「任务列表」和「分析」两个标签页。
-
任务列表(TaskTable)
-
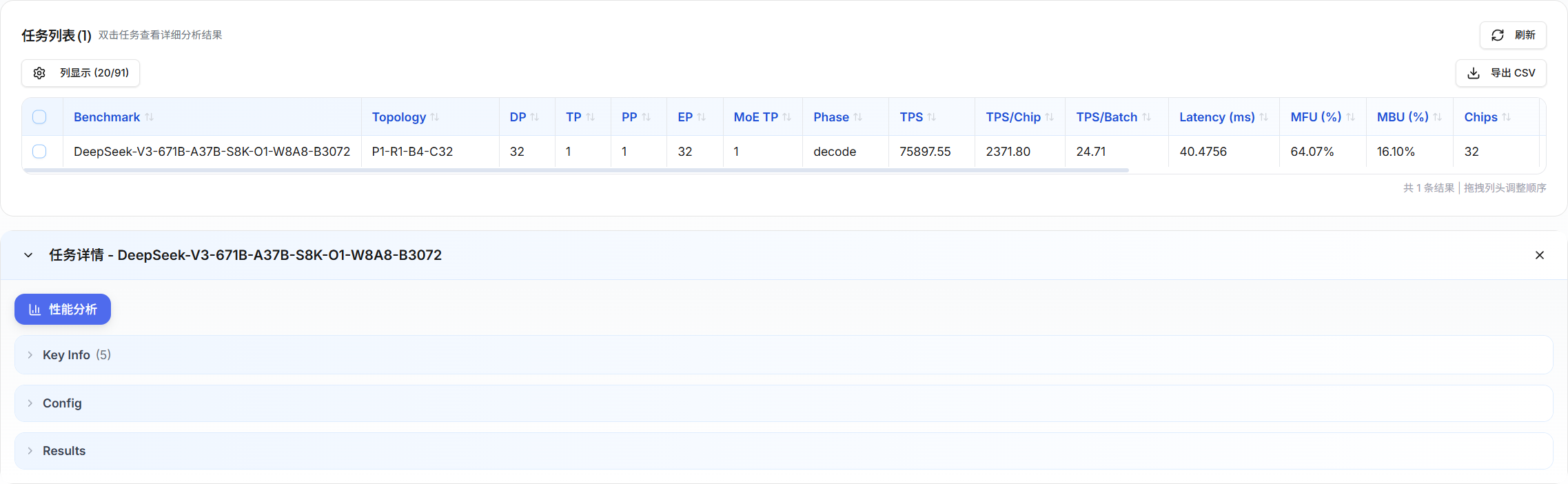
-
任务列表采用类 Excel 的表格组件展示评估任务数据。主要数据列:
列类别 包含字段 基本信息 任务名、状态、创建时间、评估阶段(Prefill/Decode) 并行策略 DP、TP、PP、EP 并行度 吞吐量指标 TPS(Decode)、TTFT(Prefill)、TPOT(Decode) 利用率指标 MFU、MBU(Prefill 和 Decode 分别显示) 成本指标 每百万 token 成本、总硬件成本 配置参数 Batch Size、Input/Output Seq Length、权重精度 -
排序:单击列标题可按该列排序(升序/降序),支持多列联合排序。
-
导出 CSV:点击表格右上角的「导出」按钮,将当前可见列的所有任务数据导出为 CSV 文件,可在 Excel 中打开进一步分析。
-
-
列配置管理
- 任务表格支持对列的显示、顺序和固定进行自定义配置,并持久化保存:
- 点击表格右上角的「列设置」按钮,打开列配置面板。
- 勾选/取消勾选列名,控制该列的显示或隐藏。
- 在列配置面板中拖拽列名,调整列的显示顺序。
- 点击列名旁的「固定」按钮,将该列固定到表格左侧(不随横向滚动而移动)。
- 配置完成后点击「保存」,配置写入数据库,刷新页面后仍保持。
- 将常用的列配置方案保存为命名预设,在不同分析场景之间快速切换:
- 完成列配置后,在预设名称输入框中填写名称,点击「保存预设」。
- 需要加载时,从预设下拉框中选择已保存的预设名称。
- 支持删除不再使用的预设。
- 任务表格支持对列的显示、顺序和固定进行自定义配置,并持久化保存:
任务分析视图
-
在任务列表中,点击某行的「查看详情」操作,进入该任务的完整分析视图。顶部面包屑导航:实验列表 -> 实验详情 -> 任务分析,可点击各层级跳转。
-
KPI 面板
指标 说明 TPS Tokens/秒(系统总吞吐量) TPOT ms/token(单 token 生成时延) TTFT ms(首 token 延迟) MFU 算力利用率(0-1) MBU 带宽利用率(0-1) -
MFU 与 MBU 解读
- Decode 阶段(小 Batch Size)算术强度低,通常 MBU 高、MFU 低,属正常现象——此阶段内存带宽是瓶颈,不需要追求高 MFU。
- Prefill 阶段(长序列)算术强度高,MFU 更有参考价值。
-
评分雷达图
- 多维度评分的雷达图(吞吐量、延迟、算力利用率、带宽利用率、成本效益等维度),满分 100 分。
-
甘特图
- 横轴为时间(us),纵轴为各计算/通信操作。不同颜色区分计算操作与通信操作。解读要点:
- 计算块与通信块在时间轴上重叠,说明计算-通信重叠优化生效。
- 通信块占总时间比例过大(>50%),说明通信是性能瓶颈,可考虑调整 TP/PP 分配或启用 Ring Attention/TBO 优化。
- 某一层的时间远长于其他层,说明该层是性能热点,重点关注其算子构成。
- 横轴为时间(us),纵轴为各计算/通信操作。不同颜色区分计算操作与通信操作。解读要点:
-
Roofline 图
- 横轴为算术强度(FLOP/Byte),纵轴为有效吞吐量(TFLOPS)。解读要点:
- 数据点落在内存屋顶线(斜线区域)左侧:内存带宽是瓶颈。
- 数据点落在计算屋顶线(水平线区域)右侧:算力是瓶颈。
- 数据点接近计算屋顶且 MFU 高为理想状态,说明硬件资源被充分利用。
- 横轴为算术强度(FLOP/Byte),纵轴为有效吞吐量(TFLOPS)。解读要点:
-
内存占用柱状图
- 以堆叠柱状图展示各阶段的显存占用构成:模型参数(蓝色)、KV Cache(浅蓝色)、激活值(更浅蓝色)。
- 若 KV Cache 一栏过高,可考虑缩短序列长度、启用 FP8 量化或选用含 MLA 的 DeepSeek 模型。
-
算子时间分解图
- 展示各类算子在总推理时间中的占比(Attention 计算、FFN、AllReduce 通信、AllToAll 通信等)。
- 若 AllToAll 通信占比显著,说明 MoE 专家路由通信开销大,可考虑启用 TBO 优化或调整 EP 策略。
-
拓扑流量图
- 芯片间通信流量的热力图,颜色深浅反映通信量大小。
-
层级瀑布图
- 逐层性能分解(每层的计算时间 + 通信时间)。
导入与导出
-
导出实验
- 在实验列表页面,勾选需要导出的一个或多个实验。
- 点击工具栏中的「导出」按钮。
- 在弹出对话框中确认所选实验列表。
- 点击「确认导出」,浏览器自动下载 JSON 格式的导出文件。
- 导出文件包含:实验元数据(名称、描述)、所有任务的完整配置快照(含芯片/模型/拓扑/并行策略参数)和完整评估结果,可用于跨机器共享或长期归档。
-
导入实验
- 导入分为 4 个步骤:
- 上传文件:点击工具栏中的「导入」按钮,选择之前导出的 JSON 文件,文件上传后自动进入下一步。
- 冲突检查:系统自动检测导入数据中是否存在与本地同名的实验,显示冲突列表供用户确认。
- 冲突策略配置:选择以下策略之一:跳过(Skip)——冲突实验不导入,非冲突实验正常导入;覆盖(Overwrite)——用导入数据替换本地同名实验(原有任务结果被删除);重命名(Rename)——在冲突实验名称后自动追加时间戳后缀,以新名称导入,本地原实验保留。
- 结果确认:系统显示导入完成的汇总信息(成功数、跳过数、失败数)。
- 注意:覆盖操作会永久删除本地同名实验的所有历史任务结果,不可恢复。如有疑虑,建议先选择「重命名」策略,确认导入数据完整后再决定是否删除旧实验。
- 导入分为 4 个步骤:
知识网络
页面概述
-
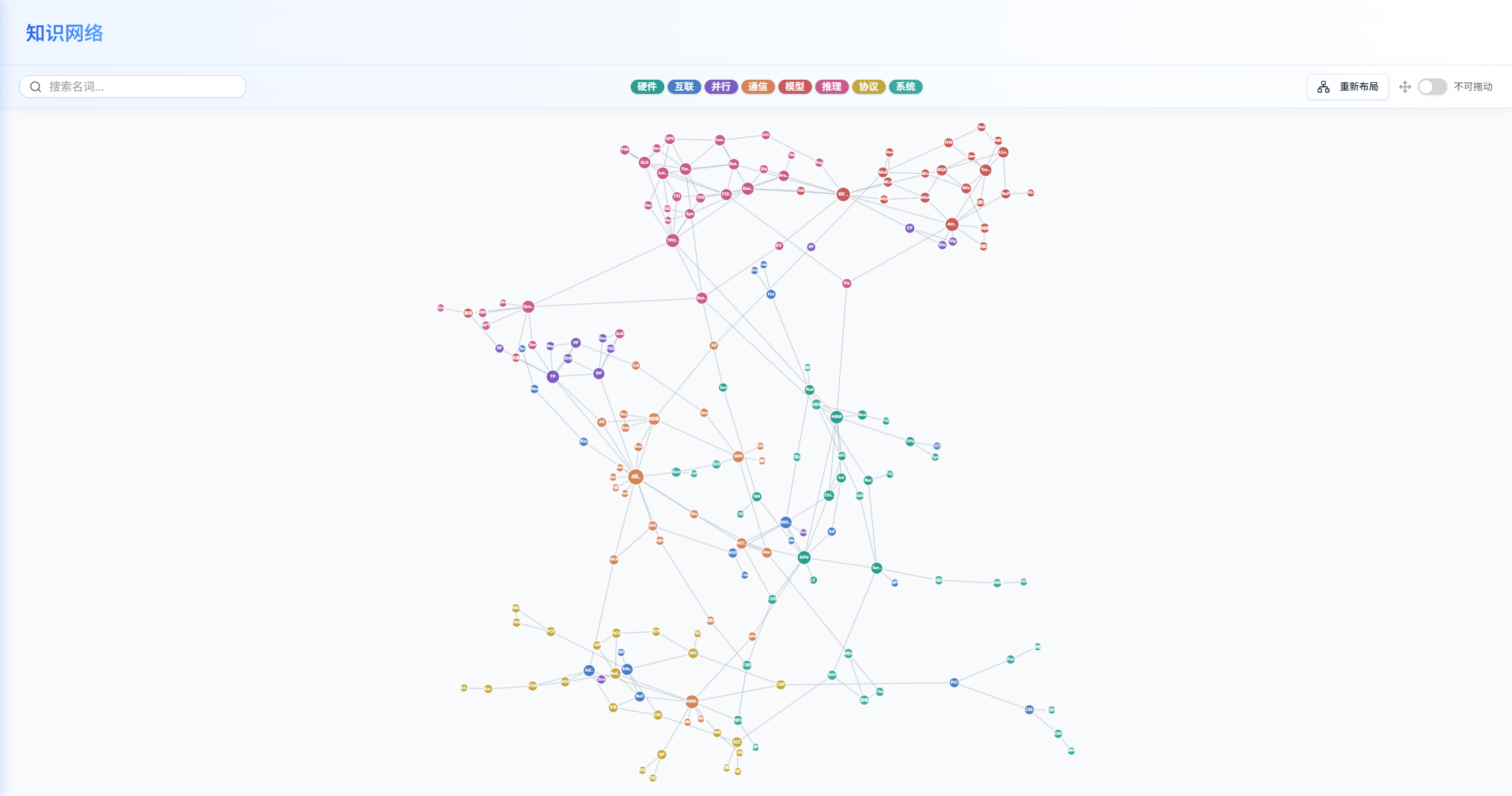
-
知识网络提供分布式计算与 LLM 推理领域概念的交互式知识图谱,帮助用户理解各概念之间的关联关系(如并行策略、通信算法、硬件架构等概念的相互依赖)。
界面布局
- 左侧面板:概念搜索框和概念列表,支持按关键词搜索和分类筛选。面板宽度可拖拽调整(200-600px)。
- 右侧区域:力导向图可视化,以节点和连线展示概念及其关联关系。
操作方式
-
支持的交互操作:
操作 方式 效果 搜索概念 在搜索框中输入关键词 左侧列表筛选匹配的概念,图中对应节点高亮 查看概念详情 单击图中节点 左侧面板显示该概念的详细说明和关联概念列表 平移视图 鼠标拖拽画布 移动知识图谱的显示位置 缩放视图 鼠标滚轮 放大或缩小知识图谱 自适应画布 工具栏"适应"按钮 图谱自动缩放以填满当前显示区域
常见问题与故障排查
启动问题
-
问题:浏览器访问
http://localhost:3100显示"无法连接"或页面空白。- 排查:检查前端服务是否正常启动。查看启动脚本的命令行窗口中是否出现 Vite 的启动成功提示("Local: http://localhost:3100/")。
- 解决:若端口 3100 被占用,Vite 会自动切换到其他端口(如 3101),查看命令行实际端口号后访问对应地址。
-
问题:页面显示正常,但 Benchmark/模型预设列表为空或加载转圈。
- 排查:后端服务未正常启动。访问
http://localhost:8003/docs,若无响应则后端未启动。 - 解决:查看后端命令行窗口的错误日志;确认 8003 端口未被占用;检查
frontend/.env中VITE_API_PORT是否为 8003。
- 排查:后端服务未正常启动。访问
-
问题:
pip install -r requirements.txt报依赖版本冲突。-
解决:在 Python 虚拟环境中安装可隔离冲突:
# Windows
python -m venv .venv
.venv\Scripts\activate
pip install -r requirements.txt
# Linux/macOS
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
-
-
问题:
pnpm install报网络错误或超时。- 解决:配置 pnpm 国内镜像:
pnpm config set registry https://registry.npmmirror.com,再重新执行安装。
- 解决:配置 pnpm 国内镜像:
配置问题
-
问题:手动模式下并行度设置后出现红色错误提示,无法提交。
- 原因:DP x TP x PP 的乘积不等于当前拓扑的总芯片数。
- 解决:检查并行度配置。总芯片数 = Pod 数 x Rack/Pod x Board/Rack x Chip/Board,在拓扑配置卡片中查看。
-
问题:选择某个模型后,MLA 或 MoE 参数区域消失。
- 原因:所选模型不含 MLA 或 MoE 特性(enabled: false),参数区域自动隐藏,属正常行为。
-
问题:修改了芯片参数后提交评估,结果与预期不符。
- 排查:确认配置名称旁是否有橙色修改标记;若无,说明修改未被保存,重新在配置面板中修改后再提交。
评估执行问题
-
问题:评估任务长时间停留在"运行中"或进度长时间不更新。
- 排查:访问
http://localhost:8003/docs确认后端服务仍在运行;查看后端命令行日志是否有错误输出。 - 解决:点击「取消」中止任务,根据错误日志排查问题后重新提交。
- 排查:访问
-
问题:自动搜索模式长时间未出结果。
- 原因:搜索空间过大(如 32 片或以上时候选方案数量可达数百至数千)。
- 解决:点击「取消」中止搜索,改为手动模式评估特定方案,或配置更严格的搜索约束(如减少最大迭代次数)。
-
问题:参数扫描提交大量任务后,其他任务长时间排队等待。
- 原因:默认最大并发数(4)限制了同时运行的任务数量。
- 解决:在分析配置的「最大并发数」中增大并发数(根据机器 CPU 核数合理设置,建议不超过 CPU 核心数 / 2)。
结果查看问题
-
问题:评估完成后,「结果管理」页面没有出现新实验。
- 排查:检查「部署分析」的分析配置中「任务名称」字段是否已填写;任务状态是否为"已完成"(而非"失败")。
- 解决:在分析配置卡片中填写有意义的任务名称后重新提交;若任务失败,查看后端日志中的错误信息。
-
问题:详细结果视图中某些图表区域显示"暂无数据"。
- 排查:确认分析配置中对应的评估阶段已勾选(如甘特图需要 Prefill 或 Decode 阶段的评估结果)。
-
问题:MFU 显示值极低(如 0.001),是否异常?
- 解答:Decode 阶段 Batch Size=1 时,算术强度极低,几乎完全由内存带宽决定性能,MFU 天然很低,属正常现象。此时应关注 MBU(内存带宽利用率)指标。
-
问题:参数敏感性分析的图表为空或无数据点。
- 原因:实验下的任务数量不足(单参数折线图需要至少 2 个不同参数值的任务,双参数热力图需要 4 个以上任务),或所选参数在各任务间没有变化。
- 解决:使用参数扫描模式提交多组参数组合的任务,再在实验详情中进行分析。
CheckList
- table@checklist
- Cat.: 环境搭建
- Check 项目: Python 版本检查
- Check 方法: 在终端执行
python --version,确认版本号 - 参考值: Python 3.10 或以上版本
- Check 方法: 在终端执行
- Check 项目: Node.js 版本检查
- Check 方法: 在终端执行
node --version,确认版本号 - 参考值: v18.0.0 或以上版本
- Check 方法: 在终端执行
- Check 项目: 后端依赖安装
- Check 方法: 在项目根目录执行
pip install -r requirements.txt,观察输出 - 参考值: 所有包安装成功,无 ERROR 输出(WARNING 可忽略)
- Check 方法: 在项目根目录执行
- Check 项目: 前端依赖安装
- Check 方法: 在 frontend/ 目录执行
pnpm install,观察输出 - 参考值: 安装完成,node_modules 目录存在,无 ERR 输出
- Check 方法: 在 frontend/ 目录执行
- Check 项目: 平台前端启动
- Check 方法: 执行 start.bat(Windows)或 ./start.sh(Linux),浏览器打开 http://localhost:3100
- 参考值: 显示概览页面(Dashboard),左侧导航栏包含完整功能菜单(概览/互联拓扑/部署分析/结果管理/知识网络),4 个快速操作卡片可见
- Check 项目: 后端 API 可访问
- Check 方法: 浏览器访问 http://localhost:8003/docs
- 参考值: 显示 FastAPI Swagger 文档页面,API 端点列表非空(说明后端路由注册正常),页面标题包含"Tier6"
- Check 项目: 前后端连通性
- Check 方法: 进入「部署分析」页面,点击 Benchmark 预设下拉框
- 参考值: 下拉列表显示至少 1 个预设选项(非空),不出现"加载失败"或转圈超过 5 秒
- Check 项目: Python 版本检查
- Cat.: 互联拓扑配置
- Check 项目: 预设拓扑加载
- Check 方法: 进入「互联拓扑」页面,在拓扑选择器下拉框中选择 P1-R1-B1-C8
- 参考值: 层级参数自动填充(Pod=1, Rack=1, Board=1, Chip=8),3D 视图渲染出 8 个芯片节点
- Check 项目: 3D 视图基本交互
- Check 方法: 在 3D 视图中依次执行鼠标左键拖动(旋转)、滚轮滚动(缩放)、右键拖动(平移)
- 参考值: 视图响应流畅,旋转角度跟随鼠标方向,缩放后芯片节点大小改变,平移位移正确
- Check 项目: 层级下钻与返回
- Check 方法: 在 3D 视图中双击某个节点进入子层级,然后按 ESC 返回上级
- 参考值: 成功切换到子层级视图,顶部面包屑导航路径更新,按 ESC 后返回上级,面包屑路径缩短
- Check 项目: 芯片硬件参数编辑
- Check 方法: 修改 compute_tflops_bf16 数值后切换到其他配置项再切回
- 参考值: 修改后的数值被保留,配置名称旁出现橙色修改标记
- Check 项目: 互联参数配置
- Check 方法: 修改 c2c 互联的带宽值(如改为 512),确认是否接受输入
- 参考值: 输入框接受新数值,无报错,数值显示为 512
- Check 项目: 预设拓扑加载
- Cat.: 部署分析 - 配置
- Check 项目: Benchmark 预设加载
- Check 方法: 进入「部署分析」,从 Benchmark 预设下拉框选择任意预设
- 参考值: 模型名称、拓扑名称、Batch Size、Seq Length 等字段自动填充,无字段显示为空
- Check 项目: 模型预设切换(MoE/MLA 字段显隐)
- Check 方法: 在模型选择器中从 DeepSeek-V3 切换到 Qwen2.5-72B
- 参考值: 切换后 MoE 和 MLA 参数区域消失(Qwen2.5-72B 为稠密模型,两者均为 disabled)
- Check 项目: 推理参数修改标记
- Check 方法: 修改 Batch Size 为 32,观察 Benchmark 名称旁的状态
- 参考值: Benchmark 名称旁出现橙色修改标记(提示当前配置与预设不同)
- Check 项目: 手动模式并行度校验(合法输入)
- Check 方法: 使用 P1-R1-B1-C8(8 芯片)拓扑,手动模式设置 DP=2, TP=4, PP=1
- 参考值: DPTPPP=8=总芯片数,无红色错误提示,「运行分析」按钮处于可点击状态
- Check 项目: 手动模式并行度校验(非法输入)
- Check 方法: 手动模式下设置 DP=3, TP=4, PP=1(乘积=12,不等于总芯片数 8)
- 参考值: 显示红色错误提示说明乘积与芯片数不符,「运行分析」按钮置灰不可点击
- Check 项目: 自动搜索模式切换
- Check 方法: 将并行策略模式切换到「自动搜索」,观察页面变化
- 参考值: 手动并行度输入框消失,出现搜索约束配置项,「运行分析」按钮仍可点击
- Check 项目: 参数扫描模式配置
- Check 方法: 切换到「参数遍历」模式,添加 batch_size 参数(起始 1、结束 4、步长 1),查看组合数
- 参考值: 页面显示总组合数为 4,提交后将产生 4 个评估任务
- Check 项目: Benchmark 预设加载
- Cat.: 部署分析 - 执行与结果
- Check 项目: 手动模式单次评估执行
- Check 方法: 配置合法的并行策略,填写任务名称,点击「运行分析」
- 参考值: 右栏出现进度指示,进度百分比从 0% 开始增长,60 秒内完成,历史记录列表中出现新条目
- Check 项目: 评估结果 KPI 合理性
- Check 方法: 评估完成后查看 KPI 面板中的各项指标
- 参考值: TPS > 0,MFU 在 0 到 1 之间,MBU 在 0 到 1 之间,TPOT > 0,TTFT > 0
- Check 项目: 评估任务取消
- Check 方法: 评估执行期间点击「取消」按钮
- 参考值: 进度条停止增长,任务状态显示为"已取消",右栏不再更新进度
- Check 项目: 甘特图渲染
- Check 方法: 评估完成后进入详细结果视图,找到甘特图
- 参考值: 甘特图显示至少一个非空的时间线(有彩色时间块),横轴有时间刻度(us),纵轴有操作名称标签
- Check 项目: Roofline 图渲染
- Check 方法: 在详细结果视图中找到 Roofline 图
- 参考值: 图中显示屋顶线(斜线段 + 水平线段),至少一个数据点分布在坐标系中,X/Y 轴均有标签
- Check 项目: 手动模式单次评估执行
- Cat.: 结果管理
- Check 项目: 实验列表加载
- Check 方法: 进入「结果管理」页面,等待列表加载完成
- 参考值: 实验列表表格加载完成(无转圈),显示实验名称、创建时间、任务数列,无报错提示
- Check 项目: 实验内联编辑持久化
- Check 方法: 双击某实验名称,修改为新名称并保存,然后刷新浏览器页面
- 参考值: 刷新后显示修改后的名称,确认修改已持久化(未恢复为旧名称)
- Check 项目: 进入实验详情
- Check 方法: 点击某实验名称进入详情,查看任务列表标签页
- 参考值: 以类 Excel 表格展示任务数据,包含并行策略(DP/TP/PP)和性能指标(TPS/TPOT/MFU/MBU)列
- Check 项目: 列配置管理持久化
- Check 方法: 在任务表格中点击「列设置」,隐藏「MBU」列并保存,然后刷新页面
- 参考值: 刷新后「MBU」列仍然隐藏,确认列配置已持久化到数据库
- Check 项目: 任务 CSV 导出
- Check 方法: 在任务表格中点击「导出」按钮
- 参考值: 浏览器下载 CSV 文件,文件大小 > 0,用文本编辑器打开第一行包含列名(如 task_name, TPS, MFU 等)
- Check 项目: 参数敏感性分析(单参数折线图)
- Check 方法: 在实验详情的「分析」标签中,选择 1 个参数(如 batch_size)和 1 个指标(如 TPS),点击生成图表
- 参考值: 折线图正常渲染,X 轴为 batch_size 取值,Y 轴为 TPS 值,折线数据点数量等于该参数的扫描点数
- Check 项目: 实验导出
- Check 方法: 在实验列表中勾选 1 个实验,点击「导出」并下载
- 参考值: 浏览器下载 JSON 文件,文件大小 > 0,用文本编辑器打开可见 experiments 和 tasks 字段
- Check 项目: 实验导入(重命名冲突策略)
- Check 方法: 点击「导入」,选择刚导出的 JSON 文件,冲突策略选择「重命名」,执行导入
- 参考值: 导入完成提示成功,实验列表中出现新条目,名称与原实验相同但带时间戳后缀
- Check 项目: 批量删除
- Check 方法: 勾选 1-2 个测试用实验,点击「批量删除」并在确认对话框中确认
- 参考值: 确认后被选实验从列表中消失,其余实验不受影响,刷新页面后确认删除已持久化
- Check 项目: 实验列表加载
- Cat.: 知识网络
- Check 项目: 知识图谱加载
- Check 方法: 进入「知识网络」页面,等待页面完成加载
- 参考值: 力导向图中出现节点和连线(节点数 >= 10),左侧概念列表非空,页面无报错
- Check 项目: 节点点击交互
- Check 方法: 单击知识图谱中的任意节点
- 参考值: 被点击节点高亮显示,左侧面板更新显示该概念的名称、说明文字和关联概念列表(至少显示 1 个关联概念)
- Check 项目: 知识图谱加载